農業分野における衛星データ利用事例¶
この章で学習すること¶
本章では、茨城県を対象として、過去約10年間のMODISデータを解析することで米の収量予測にチャレンジします。
pyMODISを用いたMODIS衛星画像処理gdal&numpyを用いた画像処理rasterstatを用いた画像における統計情報の取得
背景¶
持続可能な開発目標(SDGs)の目標2「飢餓をゼロに」では、飢餓を終わらせるため、持続可能な農業を促進することが目標に定められています。直接農業に関わるターゲットは以下の通りです(数字はターゲット番号)。
- 小規模食料生産者の農業生産性及び所得の倍増(2.3)
- 持続可能な食料生産システムの確保とレジリエントな農業の実践(2.4)
- 開発途上国の農業生産能力の向上(2.a)
- 世界の農産物市場における貿易制限や歪みの是正と防止(2.b)
適切な農業経営や生産性向上のためには、作物の状況を正しく把握して判断することが重要です。既に先進的な農家はリモートセンシングの技術を導入しており、圃場単位ならドローン、広範囲に広がる場合は衛星が利用され始めています。
また、現在、農林水産省はICT技術等を活用した新たな農林水産統計調査の効率化を目指し、気象データと人工衛星から取得されるデータを用いて水稲収量の予測に取り組んでおり、現地調査に掛かる人員の効率化に取り組んでいます。詳細は農林水産省水稲の作柄に関する委員会の配布資料を参照してください。
この章では、2007年から2017年までのMODISのデータを解析し、茨城県全体を対象として水稲の収量を予測する式を作成し、2018年のデータで検証する方法を学んでいきます。
準備¶
# google driveをマウント
# Tellusの開発環境やローカル環境を使用する想定であれば、このセルは削除可です。
from google.colab import drive
drive = drive.mount('/content/drive')
必要なライブラリのインストール¶
!pip install pyMODIS
!pip install geopandas
!pip install pandas
!pip install matplotlib
!pip install numpy
!pip install scikit-learn
ライブラリのインポート¶
基礎分野でご紹介したGDALライブラリは、地理空間データを扱う上で基礎となる重要なライブラリですが、GISの概念に慣れていないと理解しにくいパラメータがたくさん登場するため、衛星データを触り始めたばかりの頃は複雑に感じることもあるかと思います。
この教材では、地理空間データの処理がより便利になるPythonのライブラリをいくつかご紹介します。
-
numpyは、数値計算を効率的に行うための拡張モジュールです。基本的な計算はpythonだけでも出来ますが、numpyを使うとその計算が高速になったり、より楽になったりします。多次元配列を必要とする処理において、特にその機能を発揮するライブラリです。 -
有名なデータ処理ライブラリ
pandasを、地理情報が取り扱いできるように拡張したライブラリです。pandasと同じ強力なデータ処理機能を持つだけでなく、他の地理空間データとの連携が可能です。 -
matplotlibは、Pythonでグラフや図を描画、作成するための包括的なライブラリです。折れ線グラフやヒストグラムといった2次元グラフだけなく3次元のグラフも描画することが可能です。 -
pyMOIDSは、GNU GPL 2によって管理されているライブラリで、NASAが運用する衛星センサ"MODIS"のデータ処理専用のライブラリです。NASAのサーバから直接MODISデータをダウンロードして投影変換などの処理することが可能です。 -
scikit-learnは、オープンソースで公開されている機械学習用のライブラリです。誰でも無償で利用することが可能であり、分類/回帰/クラスタリングといったモデルを作成することが可能です。
#必要ライブラリをインポート
import os
import glob
import numpy as np
import math
import matplotlib
import matplotlib.pyplot as plt
import shutil
import pandas as pd
import geopandas as gpd
import csv
import requests,urllib
from pymodis import downmodis
from pymodis.convertmodis_gdal import convertModisGDAL
from osgeo import gdal, gdalconst, gdal_array, osr
from sklearn.linear_model import LinearRegression
from sklearn import linear_model
print("done")
衛星データの取得¶
この章では、アメリカ航空宇宙局(NASA)が運用するTerra衛星およびAqua衛星に搭載されている光学センサ「MODIS」が取得するデータを使用します。このデータは誰でも無償で利用することが可能です。
Terra衛星の緒言についてはリモート・センシング技術センターのサイトを参照してください。
MODISについて¶
MODISは36種類の異なる波長帯(バンド)で地球を観測しており、プロダクトは以下の5種類に大別されます。
- 放射輝度データ等(レベル1データ)
- 大気プロダクト
- 陸域プロダクト
- 氷圏プロダクト
- 海洋プロダクト
一般的にリモートセンシング技術を用いて植生を解析する際に用いられる代表的な指標としてNDVIとEVIが挙げられます。
今回は陸域プロダクトの1つであるMODIS Vegetation Index ProductよりEVIのデータを使用します。
コラム1:NDVIとEVI¶
光学衛星による植生の状況把握では、植生が強く反射する近赤外線および植生が吸収する可視域の赤色の波長がよく用いられます。この波長帯の組み合わせによって、植物の状態を表す正規化植生指数(Normalized Difference Vegetation Index: NDVI)を計算することができます。NDVIについては森林分野を参照して下さい。
NDVIの精度を向上させた植生の指標として、EVI (Enhanced Vegetation Index) も用いられています。
EVIは以下の式で求めることができます。
$EVI = \frac{G ×(IR - Red)}{(IR + C1 × Red)- (C2 × Blue + L)}$
ここで、Gはゲイン係数、C1とC2はエアロゾル補正係数、Lは背面効果補正係数を表しており、MODISのEVIプロダクトの場合、以下の数値が用いられています。
G = 2.5, C1 = 6, C2 = 7.5, L = 1
EVIは、近赤外線および赤色に加え、青色の波長帯を使うことで高バイオマス地域での感度を改善し、キャノピーのバックグラウンド信号の分離と大気の影響の低減を通じて植生モニタリングを改善して、植生信号を強化するように設計された「最適化された」植生指数です。
本章では、水稲の生育開始前と生育のピーク時(8月から9月)における差が明確に表れ、また、大気の影響に強く季節変化を捉えやすいと考えられるEVIを用いることとした。
API経由のデータ取得¶
APIを使ってMODISのデータをダウンロードするためには、NASAのEARTH DATAにアクセスして、ユーザー登録をしてください。
本章では、2007年から2017年までのMODISのデータを解析して収量を予測する式を作成し、2018年のデータで検証してみます。
そこで、NASAのLP DAAC (Land Processes Distributed Active Archive Center) よりAPI経由でデータをダウンロードし、対象期間のデータセットを作成します。
#解析対象期間の指定とデータ保存用ディレクトリ(フォルダ)の作成
list = ["2007","2008","2009","2010","2011","2012","2013","2014","2015","2016","2017","2018"]
os.mkdir("average_EVI")
print("done")
本章では、Vegetation Indices 16-Day L3 Global 250mプロダクトを使用します。このプロダクトは、日別のEVIデータ16日分を合成することで雲の影響を減少させたものです。MODISのデータはほぼ毎日取得されますが、このプロダクトは16日ごとに提供されています。
また、プロダクト画像はシヌソイダル座標系で区切られ、各地域によってタイル番号が振られています。タイル番号についてはこちらを参照してください。
一般的に水稲収量を予測する際には植生指標の積算値が用いられますが、本章では水稲の植生指数が最も高くなる8月と9月で2時期のEVIを平均化して代表値とします。
また、8月と9月それぞれの代表プロダクトは画像を見て適切な組み合わせを選択しました。
ダウンロードしたデータにはそれぞれ異なるプロダクトがHDF形式で格納されているので、上記プロダクトを抜き出し、UTM zone 54Nの座標系を与え、GeoTIFF形式で保存します。
for a in list:
# 年ごとにデータ保存先のフォルダを作成
os.mkdir(a)
dest = "/content/" + a
# タイル番号で取得するエリアを指定(茨城を取得するのでh29v05)
tiles = "h29v05"
# 代表プロダクトの組み合わせを下記のif文で指定
if a == "2012":
MODIS_date_After = "-09-20"
MODIS_date_Before = "-08-25"
elif a == "2013":
MODIS_date_After = "-09-20"
MODIS_date_Before = "-08-25"
elif a == "2014":
MODIS_date_After = "-09-20"
MODIS_date_Before = "-08-25"
else:
MODIS_date_After = "-09-30"
MODIS_date_Before = "-09-01"
#データの検索期間を指定
#検索期間のゴールを指定
day = a + MODIS_date_After
print(day)
#検索期間のスタートを指定
eday = a + MODIS_date_Before
print(eday)
#欲しいプロダクトを指定
product = "MOD13Q1.006"
#NASA Earthdataのアカウントユーザー名
name = "ユーザー名を「””」の中に記入してください"
#NASA Earthdataのアカウントパスワード
path="アカウントパスワードを「””」の中に記入してください"
#ダウンロード先のディレクトリを指定
datapath = "/content/" + a
#データのダウンロード
modisDown = downmodis.downModis(destinationFolder=dest, product=product, user=name, password=path, tiles=tiles, today=day, enddate=eday)
modisDown.connect()
modisDown.downloadsAllDay()
#使用するデータの選択
hdf_list = glob.glob(os.path.join(datapath, 'MOD13Q1.*.hdf'))
print(hdf_list)
# EVIの抜出と投影変換
for f in hdf_list:
print(f)
output_pref = "/content/" + a + "/" + str(f[14:])
#HDFファイルに格納されているデータの数分のリスト。投影変換したいプロダクトを1,無視するものを0とする。
#subsetのリストの長さはプロダクトによって異なります。本章の場合、EVI(250m)を使用するため左から2番目を"1"にする。
subset = [0,1,0,0,0,0,0,0,0,0,0,0]
convertsingle = convertModisGDAL(hdfname=f, prefix=output_pref, subset=subset, res=250, epsg=32654)
convertsingle.run()
#年ごとの平均値画像の作成
EVI_list = glob.glob(datapath + "/" + "*EVI.tif")
print(EVI_list)
src = gdal.Open(EVI_list[1], gdalconst.GA_ReadOnly)
img = np.array(src.ReadAsArray()).astype(np.float32)
pixel=img.shape[0]
line=img.shape[1]
base_array = np.zeros((pixel,line))
for EVI in EVI_list:
print("OPEN" + EVI)
data = gdal.Open(EVI, gdalconst.GA_ReadOnly)
imgs = np.array(data.ReadAsArray()).astype(np.float32)
base_array = base_array + imgs
base_array
EVI_ave = base_array/len(EVI_list)
array = EVI_ave
xsize = src.RasterXSize
ysize = src.RasterYSize
geotransform = src.GetGeoTransform()
print("make EVI average image")
dst = os.path.join("/content/average_EVI/" + "EVI_average_" + a + ".tif")
driver = gdal.GetDriverByName('GTiff')
dst_raster = driver.Create(dst, xsize, ysize, 1, gdal.GDT_Int16)
dst_raster.SetProjection(src.GetProjection()) #{出力変数}.SetProjection(座標系情報)
dst_raster.SetGeoTransform(src.GetGeoTransform()) #{出力変数}.SetGeoTransform(座標に関する6つの数字)
dst_band = dst_raster.GetRasterBand(1)
dst_band.WriteArray(EVI_ave)
dst_band.FlushCache()
dst_raster = None
print("done")
サンプルとして2007年におけるEVI平均値画像を表示してみましょう。
EVI_image = gdal.Open("/content/average_EVI/EVI_average_2007.tif")
EVI_array = EVI_image.ReadAsArray()
plt.figure(figsize=(20,10))
plt.imshow(EVI_array,vmin=-3000,vmax=10000,cmap='RdYlGn')
plt.title("EVI 2007")
plt.colorbar()
plt.show

上の画像ではEVIの範囲を-3000から10000で表示しています。 画像において緑色が強いほど植物の活性が高いことを示しており、赤が強いほど植生が少ないことを示しています。 また、水域が赤く染まっていますが、こちらは水域を無効値である-3000であることを示しています。
画像を見ると、東京都や神奈川県などの都市部においては赤色が強く、植生が少ないことが見て取れます。
水田域におけるEVIの集計¶
今回の解析では、茨城県を対象に水稲の収量を予測します。茨城県全域のEVIを解析すると、水田以外に畑や森林の植生も入ってしまうので、水田以外をマスク(隠す)した上で、水田域におけるEVIの平均値を計算します。
筆ポリゴンの取得¶
マスク処理には、農林水産省が提供している農地の区画情報である「筆ポリゴン」を使用します。筆ポリゴンは、都道府県あるいは市町村単位で提供されているGISデータ(Shapefile)です。
本来ならば、解析する年ごとに筆ポリゴンを入手する必要がありますが、過去のアーカイブは提供されていません。今回は、過去10年間の農地の変化は誤差の範囲として割り切り、提供されている最新版の筆ポリゴンを使って過去のEVIもマスクすることにします。
農林水産省ウェブサイトの筆ポリゴンダウンロードページから、茨城県の筆ポリゴンデータをダウンロードしましょう。zip形式で圧縮されたファイルを解凍すると、市町村単位のフォルダでファイルが格納されています。
筆ポリゴンの編集¶
市町村単位で提供されている筆ポリゴンを結合し、茨城県全体のデータを作成しましょう。
また、ポリゴン情報の中には「田」だけでなく「畑」の情報も格納されています。今回は水稲の収量を予測するので、畑のポリゴンを取り除く処理をします。
今回は、フリーのGISソフトであるQGISによる手順を紹介します。QGISはこちらからダウンロードすることができます。
- QGISを開き、各フォルダに格納されているShapefile (shp) を読み込む
- メニューバーにある「ベクタ」から「データ管理ツール」を開き、「ベクタレイヤのマージ」を起動する
- 「ベクタレイヤのマージ」ウィンドウが開かれるため、以下のように設定する
- 「入力レイヤ」⇒ 各市町村のシェープフィルをすべて選択する
- 「変換先の座標参照系(CRS)」⇒ EPSG:32654 WGS84/UTM zone 54N
- 「出力レイヤ」⇒ 新規ファイル名を設定(「…」から保存先のディレクトリを選択可能)
- 「実行」をクリックすると茨城県 筆ポリゴンが出力される
- 上記4で作成した筆ポリゴンをQGISで開き、ポリゴンファイルを選択した状態でプラグインツールバーにある編集モード切替を選択する
- 上記4で作成したポリゴンファイルを選択し「属性テーブル」を開く
- 属性テーブル内にある「耕地の種類」から、「畑」の属性を持つポリゴンを選択し、削除する
- 属性テーブルを閉じ、プラグインツールバーにある「レイヤ編集内容の保存」を選択し、編集を終える
市町村単位の筆ポリゴンを結合し、水田を対象とした茨城県全体の筆ポリゴンを作成できました。Google Earthに重ねて確認してみましょう。
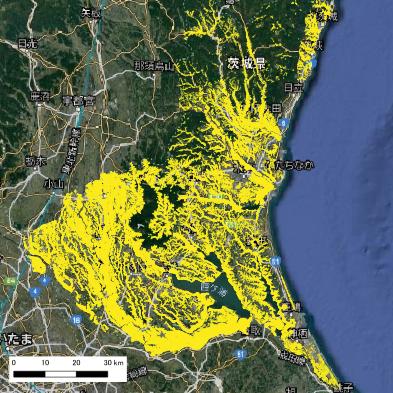
拡大して見てみましょう。水田の一筆一筆が黄色のポリゴンで囲われていることがわかります。

水田以外のマスク処理¶
作成した茨城県の水田の筆ポリゴンを利用し、再度QGISを使ってEVIのマスク画像を作成しましょう。手順は以下の通りです。
- QGISを開き、作成した茨城県の筆ポリゴンとEVIのGeoTIFF画像を表示する
- QGISのメニューバーにある「ラスタ」から「ベクタのラスタ化」を起動する
- 「ベクタのラスタ化」ウィンドウが開くので、以下のように設定して「実行」をクリックする
- 「入力レイヤ」⇒ 茨城県の筆ポリゴン
- 「固定値」⇒ 1.000
- 「出力ラスタサイズの単位」⇒ 地理単位
- 「水平方向の解像度」「鉛直方向の解像度」⇒ 250.000
- 「出力領域」⇒ 「…」から「レイヤの領域を使う」を選択し、EVIの画像を選択
- 「出力データ型」⇒ Byteを選択
- 「追加のコマンドラインパラメータ」⇒ 「-at」と入力
- 「出力ファイル」⇒ 新規ファイル名を設定(「…」から保存先のディレクトリを選択可能)
そうすると、下図のようなEVIの筆マスク画像が出力されます。
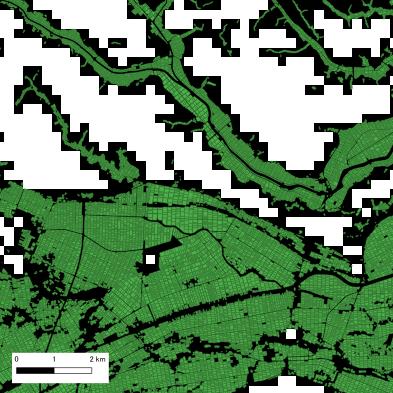
EVIの集計とグラフ表示¶
筆マスク画像を用いてEVIを集計しましょう。筆ポリゴン内で集計したEVIの値を平均値化し、その年のEVIの代表値とします。2007年から2018年まで、各年のEVI値を計算してみましょう。
# mask_pathは適宜、データが格納されているディレクトリに変更してください。
# raster_pathは適宜、データを保存したいディレクトリに変更してください。
mask_path = "/content/drive/MyDrive/fude_raster_markK.tif"
raster_path = "/content/average_EVI"
mask = gdal.Open(mask_path)
mask_a = mask.ReadAsArray()
#保存用ディレクトリからEVIのGeoTiff画像を選択
EVI_year_datas = sorted(glob.glob(os.path.join(raster_path,"*.tif")))
#集計した値を入れるリストを作成
EVI_all = []
#EVIの平均値を算出
for data in EVI_year_datas:
EVI = gdal.Open(data)
EVI_a = EVI.ReadAsArray()
evi = EVI_a * mask_a
evi_2 = np.mean(evi[evi!=0])
EVI_all.append(evi_2)
print(EVI_all)
#データフレーム化
df_EVI_all_year = pd.Series(EVI_all,index=["2007","2008","2009","2010","2011","2012","2013","2014","2015","2016","2017","2018"])
df_EVI_final = pd.DataFrame(df_EVI_all_year,columns=["EVI"])
df_EVI_final
コラム2:ポリゴンデータによる空間統計¶
本章では、QGISで処理をしたマスク画像を用いて茨城県の農地におけるEVI値を推定しました。 "rasterstas"というライブラリを用いると、筆ポリゴンなどのポリゴンファイルを用いて推定が可能です。
###sample###
"""
#ライブラリのインストール
!pip install rasterstats
from rasterstats import zonal_stats
import geopandas as gpd
import numpy as np
#raster_pathは作成したEVIのデータ、vector_pathは集計用のポリゴンファイルを指定してください。
raster_path = "/content/drive/MyDrive/aaa/"
vector_path = "/content/drive/MyDrive/fude_poly_cent_point/rice_cen_poly_32654.shp"
list_average_EVI = glob.glob(os.path.join(raster_path,"*.tif"))
list_1 = []
list_2 = []
for l in list_average_EVI:
stats = zonal_stats(vector_path,l,stats="mean",all_touched=True,geojson_out=True)
geostats = gpd.GeoDataFrame.from_features(stats)
arr = geostats.values
for n in range(geostats.shape[0]):
g = (arr[n,3])
h = f.append(g)
ave = sum(list_1)/len(list_1)
list_2.append(ave)
print(list_2)
"""
rasterstasを用いる際、筆ポリゴンのような地物数の多いポリゴンデータで統計値を取得すると、非常に長い計算時間がかってしまうため、本章では処理の高速化のためマスク画像を用いました。
筆ポリゴンのように地物数の多いポリゴンデータを取り扱う際には、前処理としてバッファ(ポリゴン等から特定の距離の範囲のエリアを作成する機能)処理を施した後、重複したポリゴン同士を結合させることにより集約化したポリゴンを作成することで、処理の負荷を軽減させることができます。
2007年から2018年までのEVIの値を算出しました。年ごとの変化がわかりやすいようにグラフで表示してみましょう。
fig= plt.figure(figsize=(12,8))
df_EVI_final.plot(title="EVI 2007 to 2018",color='g',grid=True,label="EVI",xlabel = "year",ylabel = "EVI")
plt.legend()
plt.show()

日射量がEVIに及ぼす影響¶
EVIから収量を予測する前に、気象が水田のEVIに与える影響について見てみましょう。日本の水田は灌漑が整備されているので、降水量は作物の生育にあまり影響を及ぼしません。そこで、日射量とEVIを比較してみることにします。
AMeDASデータの取得¶
日本の気象データは、気象庁の地域気象観測システム「AMeDAS(Automated Meteorological Data Acquisition System)」が取得しています。詳細については気象庁のサイトを参照してください。日射量は「日照時間」として6分単位で観測されています。
気象庁の過去の気象データ・ダウンロードページ(下図参照)で、茨城県の2007年から2018年までの日照時間のデータをCSV形式でダウンロードします。
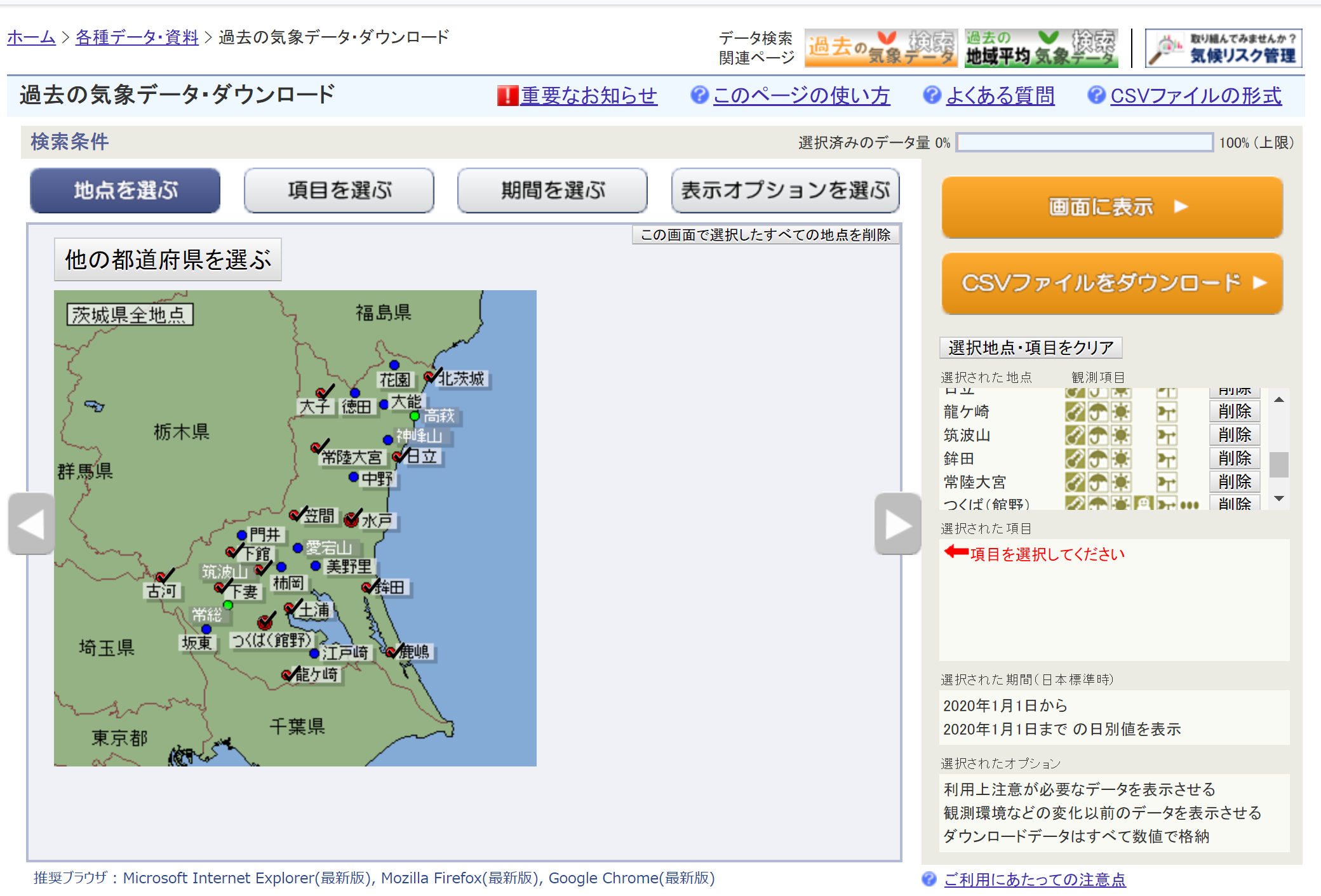
AMeDASは観測地点によって観測している対象が異なるため、日照時間を記録している地点だけを選択してください。
また、今回は8月と9月のEVIデータを取得したので、1ヶ月遡って7月から9月までの日照時間を取得し、その平均値を求め、その年の日射量の代表値とします。
コラム3:AMeDASデータの品質¶
ダウンロードしたCSVファイルには、過去の観測値に加え、選択されたオプションの組み合わせによってデータの品質情報、現象なし情報、均質番号などの値が付与されます。
- 品質情報:データが正常かどうか、欠損が無いか等を分類した値(8:正常値、5:準正常値、4:資料不足値、2:疑問値、1:欠測、0:観測・統計項目でない)
- 現象なし情報:観測点に常駐している観測員が現象の有無を記録した情報(1:現象なし、0:現象あり)
- 均質番号:データの均質性を表したもの(観測点ごとに、観測時期の古いものから、1から順番に付与される)
本章では、品質情報における正常値のみを使用して解析を行っています。
また、茨城県以外の場所で試す場合は、AMeDAS観測地点と筆ポリゴン(田)の分布が空間的に偏りがないようにデータを選択してください。
AMeDASデータの詳細についてはこちらのページを参照してください。
欠損値があるデータの削除¶
取得したデータAMeDASデータには欠損値が含まれる場合があるので、CSVファイルを調べ、欠損値がある場合にはそのデータを削除します。
#csvデータの読み込み
#csv_pathは適宜ダウンロードしたcsvファイルが保存されいているディレクトリに変更してください。
csv_path = "/content/drive/MyDrive/data.csv"
#csv_path = "/content/drive/data.csv"
df_ame = pd.read_csv(csv_path,encoding = "shift-jis")
#一行目には不要な空行があるので削除
df_ame_csv =df_ame.drop(0)
#観測地点の名称と列番号をCSVファイルを開いて確認し、リスト化
ibaraki_A_list = ["date","大子","笠間","水戸","古河","下妻","土浦","鹿嶋","日立","龍ヶ崎","筑波山","鉾田","常陸大宮","つくば(館野)","下館","北茨城"]
ibaraki_B_list = [0,1,4,7,11,14,17,20,23,26,29,32,35,38,42,45]
print("done")
#CSVファイルから必要な要素を抜出して新しい表を作成
arr = []
for i in range(len(df_ame.count(1))-1):
tmp = []
for l in ibaraki_B_list:
h = df_ame_csv.iloc[i,l]
tmp.append(h)
arr.append(tmp)
print("done")
取得したCSVファイルをデータフレーム形式で表示してみましょう。
pd.set_option("display.max_rows",150)
df_ame_csv_2 = pd.DataFrame(arr)
df_ame_csv_2.set_index(0)
データフレームの一列目には観測年と月が"年-月"の形式で表記されており、各列には観測地点と、各年の月ごとの平均値が入っています。データフレーム中にある"NaN"は数値が入っていないことを表しています。この要因として、観測や統計を行っていないこと、正常にデータが取得されなかったことなどが挙げられます。
作成したデータフレームを見ると10列目(筑波山の列)と2行目がすべてNaNとなっています。
このままだと、正しい数値が算出できないため、10列目および2行目を削除します。
#10列目の削除
df_ame_csv_3 =df_ame_csv_2.drop(columns=df_ame_csv_2.columns[10])
#2行目の削除
df_ame_csv_4 =df_ame_csv_3.drop(df_ame_csv_2.index[2])
print("done")
編集したAMeDASのデータを表示します。
df_ame_csv_5=df_ame_csv_4.set_index(0)
df_ame_csv_5
作成した表から茨城県における7月から9月の平均日射量を算出します。
amedas_sunshine_all = []
#年によって"range(7,19)"のかっこの中を変更
#集計する期間をインデックスで指定(-Jan,-Feb…,-Dec)
for y in range(7,19):
df_ame_csv_6 = df_ame_csv_5[str(y)+"-Jul":str(y)+"-Sep"]
ame_arr = df_ame_csv_6.values.astype(float)
ame_arr_ave=np.average(ame_arr)
amedas_sunshine_all.append(ame_arr_ave)
df_ame_all_year = pd.Series(amedas_sunshine_all,index=["2007","2008","2009","2010","2011","2012","2013","2014","2015","2016","2017","2018"])
df_ame_final = pd.DataFrame(df_ame_all_year,columns=["average_sunshine"])
df_ame_final
日射量とEVIの比較¶
日射量の代表値とEVIの関係をグラフで表してみましょう。
#ax1をAMeDASの日射量、ax2をEVIとして描画
fig, ax1 = plt.subplots(1,1,figsize=(10,8))
ax2 = ax1.twinx()
ax1.bar(df_ame_final.index,df_ame_final["average_sunshine"],color="orangered",label="AMeDAS")
ax2.plot(df_EVI_final["EVI"],linestyle='solid',color='g',marker='^',label='EVI')
ax1.set_ylim(100,250)
ax1.set_ylabel("AMeDAS")
ax1.set_xlabel("year")
ax2.set_ylim(2500,4000)
ax2.set_ylabel("EVI")
handler1, label1 = ax1.get_legend_handles_labels()
handler2, label2 = ax2.get_legend_handles_labels()
ax1.legend(handler1+handler2,label1+label2,borderaxespad=0)
ax1.grid(True)
fig.show()

このグラフから、日射量とEVIとの間に類似した傾向があることが見て取れます。日照時間が長ければ長いほど、水稲が順調に生育しているようです。
水稲収量の予測¶
ここまで、MODISデータから2007年から2018年の茨城県の水田のEVIを作成し、日射量による影響を見てみました。次に、2007年から2017年における水稲収量の実測値とEVIを用いて単回帰分析を行います。
また、予測式の検証として2018年のEVIを作成した予測式に当てはめ、同年の収量を予測し、推定値と実測値で比較してみることにします。
収量の実測値の取得¶
米の収量の実測値は、総務省統計局が運営するポータルサイト「e-Stat」から入手できます。このサイトは各府省が公表する統計データを管理、提供しており、APIでデータを入手することもできます。
米の収量は、kg/10aの単位で提供されてています。1a(アール)は100平方メートル(10m x 10m)です。
APIを利用するために、まずe-Statのユーザ登録のページで登録してください。
今回は、作物統計調査の水稲のデータセットから、茨城県を対象に2007年から2018年の収量情報を取得します。
また、2007年から2010年における県全体の収量がデータベース上で提供されていないことから、各市町村における収量を集計し、全体で平均値化することでその年の県全体の収量としました。
def get_json(base_url,params):
params_str = urllib.parse.urlencode(params)
url = base_url + params_str
json = requests.get(url).json()
return json
#APIを登録した際に発行されるURL
appID = "49f9da1e75db39153649b295a88a24d99b3bb56c"
base_url = "http://api.e-stat.go.jp/rest/3.0/app/json/getStatsData?"
params = {"appId":appID,"lang":"J","statsDataId":"0003293480","metaGetFlg":"Y","cntGetFlg":"N","sectionHeaderFlg":"1"}
json = get_json(base_url, params)
必要なエリアのデータを取得します。 各都道府県および市町村にIDが降られているので、e-Statのデータベースより調べリスト化します。
# 茨城県の市町村IDをリスト化
ID_list = ["08201","08202","08203","08204","08205","08207",
"08208","08210","08211","08212","08214","08215",
"08216","08217","08219","08220","08221","08222",
"08223","08224","08225","08226","08227","08228",
"08229","08230","08231","08232","08233","08234",
"08235","08236","08302","08309","08310","08341",
"08364","08442","08443","08447","08521","08542","08546","08564"]
#データのダウンロード
df_yield_base = pd.DataFrame()
for ID in ID_list:
# valuesを探す
all_values = pd.DataFrame(json['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE'])
# @cat01が110は収量(kg/10a) @areaはリストにあるIDで指定し、茨城県の市町村ごとのデータをループ処理で取得する。
values = all_values[(all_values["@cat01"] == "110") & (all_values["@area"] == ID)]
# 取得した時間の末尾に000000がつくので削除
values = values.replace("0{6}$", "", regex=True)
values = values.rename(columns = {"@time": "年", "$": "10aあたりの収量","@unit": "単位"})
values = values.astype({"10aあたりの収量":"int32"})
df_yield_base = df_yield_base.append(values)
各市町村の収量を集計し、平均値化することでその年における茨城県の収量を算出します。
year = ["2007","2008","2009","2010","2011","2012","2013","2014","2015","2016","2017","2018"]
df_yield = pd.DataFrame(columns=["年","収量合計[kg/10a]"])
#茨城県内の収量の平均値を算出
for y in year:
ind = df_yield_base[df_yield_base["年"] == y]
yield_ave = (ind["10aあたりの収量"].mean())
df_yield_sub = pd.Series([y,yield_ave], index=df_yield.columns)
df_yield = df_yield.append(df_yield_sub, ignore_index=True)
#単位を変換した年ごとの収量合計表を表示
df_yield = df_yield.set_index("年")
df_yield
#データフレームをリスト化
yield_all_df = df_yield.values.tolist()
yield_all = []
for ap in range(len(year)):
yield_all.append(yield_all_df[ap][0])
EVI値との比較¶
収量の実測値をEVIの値と並べてみましょう。
#図表用のインデックス
name=["EVI","Yield[kg/10a]"]
index_2=["2007","2008","2009","2010","2011","2012","2013","2014","2015","2016","2017"]
#集計した値のリスト
EVI = EVI_all[0:11]
y_10 = yield_all[0:11]
s1 = pd.Series(EVI,index=index_2[0:11],name=name[0])
s2 = pd.Series(y_10,index=index_2[0:11],name=name[1])
df_res = pd.DataFrame({name[0]:EVI,name[1]:y_10},index=index_2[0:11]).astype(float)
df_res
#ax1をAMeDASの日射量、ax2をEVIとして描画
fig, ax1 = plt.subplots(1,1,figsize=(10,8))
ax2 = ax1.twinx()
ax1.bar(df_res.index,df_res["Yield[kg/10a]"],color="gold",label="Yield")
ax2.plot(df_res["EVI"],linestyle='solid',color='g',marker='^',label='EVI')
ax1.set_ylim(500,600)
ax1.set_ylabel("Yield")
ax1.set_xlabel("year")
ax2.set_ylim(2500,4000)
ax2.set_ylabel("EVI")
handler1, label1 = ax1.get_legend_handles_labels()
handler2, label2 = ax2.get_legend_handles_labels()
ax1.legend(handler1+handler2,label1+label2,borderaxespad=0)
ax1.grid(True)
fig.show()

このグラフを見ると、収量とEVIの傾向は概ね同じであることがわかります。ただし、2007年や2008年のように傾向が一致しない年もあり、考察が必要です。2008年は、8月中下旬が日照不足で登熟が抑制されたようですが、その後の天候回復で収量が回復したようです(水稲の作柄に関する委員会の資料参照)。
x = df_res["EVI"]
y = df_res["Yield[kg/10a]"]
mod = LinearRegression()
df_x = pd.DataFrame(x)
df_y = pd.DataFrame(y)
#決定係数(R^2)を評価
mod_lin = mod.fit(df_x, df_y)
y_lin_fit = mod_lin.predict(df_x)
r2_lin = mod.score(df_x, df_y)
print('R = ' + str(round(math.sqrt(r2_lin), 4)))
計算した結果、R(相関係数)= 0.7 となりました。
相関係数は一般的に0.4から0.7の間であれば、正の相関が認められることからEVIと収量の間に相関関係が確認することができました。
EVIと収量の間に相関関係が確認できたので、収量を目的変数、EVIを説明変数として単回帰分析で収量予測式を作成します。
# 予測モデルを作成
clf = linear_model.LinearRegression()
x2 = s1.values.reshape(-1,1)
y2 = s2.values.reshape(-1,1)
clf.fit(x2, y2)
a = clf.coef_[0][0]
b = clf.intercept_[0]
c = clf.score(x2,y2)
plt.figure(figsize=(8, 8), dpi=80)
plt.scatter(x2, y2 ,c='#00FFFF', edgecolors="#37BAF2")
# 回帰直線の表示
plt.title('Linear regression')
plt.plot(x2, clf.predict(x2))
plt.xlabel('EVI')
plt.ylabel('Yield')
plt.grid()
plt.show()
# 各パラメータの表示 /// 表示の書き方を統一。型ををもっとシンプルな
print("回帰係数= ", clf.coef_[0][0])
print("切片= ", clf.intercept_[0])
print("決定係数= ", clf.score(x2, y2))
print("収量予測式= ", "y= " + str(a) + "x + " + str(b))

収量の予測と検証¶
作成した収量予測式を用いて2018年における収量を推定します。
#2018年の結果を予測
#集計した値のリスト
list_2018 = [EVI_all[11] ,yield_all[11]]
yield_est = (a * list_2018[0]) + b
print("2018年の収量予測値[kg/10a]:",yield_est)
print("2018年の収量実測値[kg/10a]:",list_2018[1])
#差分計算
yield_diff = yield_est - list_2018[1]
print("誤差[kg/10a]:",yield_diff)
2007年から2017年のEVIの値を用いて作成した収量予測式より2018年の収量を予測した結果、実測値に比べて約0.5 kg/10aの誤差で茨城県全体の収量を予測することができました。シンプルな予測式としてはまずまずの結果だと思います。
現在、農林水産省では複数の気象データを変数とした多変量解析による予測式の作成が取り組まれています。また、作成した予測式より上位5式を選択することで、各地域に合った予測式が作成されています。
本章ではEVIのみを使った簡単な単回帰分析で予測式を作りましたが、実際には他の変数や作物ごとの収量予測モデルが使われています。今回の方法を発展させ、複数の変数を組み合わせた予測にも挑戦してみてください。
まとめ¶
この章では、衛星データを用いて水稲収量を予測する方法について学習しました。
過去の衛星画像を時系列的に処理し推定モデルを作成するような場合、解析に用いるデータセットの品質が肝になります。解析を行う際には、画像や統計データの品質に注意し、予測が合わない場合の事由について考察することが重要です。
また、本章は解像度の低いMODISのデータを使った県単位の解析を行いました。狭い範囲を対象とする場合は別の衛星を使う必要があります。