OpenCVの使い方
Lesson
8Chapter 1
OpenCVの基本的な内容
Lesson 8Chapter 1.1
はじめに
このチャプターでは、コンピュータビジョン向けライブラリOpenCVを使った画像処理の基本的な方法を習得します。
Lesson 8Chapter 1.2
OpenCVの概要
OpenCVは、インテル社が開発したオープンソースのコンピュータビジョン向けライブラリです。
画像の読み込みや書き込み、拡大縮小・回転、色変換などの基本的な加工だけでなく、輪郭抽出やノイズ除去などのフィルタ処理、物体が写っている領域を判定する物体検出などの機能もあります。また動画ファイルを読み込んで、1コマずつ処理することもできます。
OpenCVは、さまざまなプログラミング言語から利用できるライブラリですが、本レッスンでは、Pythonから利用します。Pythonから利用する場合、読み込んだ画像イメージがNumPyの配列であるndarray形式で表現されることから、機械学習分野で画像を扱う際に、よく使われます。

Lesson 8Chapter 1.3
Pillowとの比較
Pythonで画像を扱う場合、本レッスンで使うOpenCVではなく、Pillowというライブラリも、よく使われます。Pillowは、Pythonにおける画像ライブラリとして古くから使われているものです。
PillowはOpenCVに比べて軽量なライブラリで、インストールも容易です。そのため、画像のリサイズや回転、トリミングなど、基本的な画像操作だけをしたい場面では、Pillowで十分です。
対してOpenCVはコンピュータビジョンを扱うことを目的に作られた高度なライブラリです。フィルタ機能が充実しており、ヒストグラム操作やノイズ除去、エッジ抽出、果ては物体検出までできます。
ただし逆にOpenCVにはない機能もあります。その代表が、画像の表示機能です。OpenCVで読み込んだ画像や動画を画面上で確認するときは、Pillowもしくはグラフを表示するライブラリであるmatplotlibなど、別のライブラリが必要です。
表 PillowとOpenCVとの比較
| 項目 | Pillow | OpenCV |
|---|---|---|
| ライブラリが作られた目的 | 画像処理全般 | コンピュータビジョン |
| リサイズや回転、トリミングなどの基本操作 | ○ | ○ |
| 色の変換 | △ | ○ |
| ノイズ除去 | × | ○ |
| エッジ抽出 | × | ○ |
| 物体検出 | × | ○ |
| 動画の扱い | × | ○ |
| 画像の画面への表示 | ○ | × |
Lesson 8Chapter 1.4
OpenCVと機械学習の関係
このレッスンで学ぶOpenCVの技法は、機械学習で画像データを扱う際にとても役に立ちます。画像データを用いた機械学習では、以下の点がポイントになります。
- 特徴の抽出:エッジ(輪郭)や色合い、明度の変化などの物体の本質的な特徴を抽出できる
- 移動不変性、位置不変性:物体がどこにあっても特徴を抽出できる
学習の対象となる画像データ数が少ないと、上記のような特徴をモデルが学習する前に、データの本質的ではない特徴まで過度に学習してしまい、モデルの性能が向上しなくなります。このような状態を「過学習」と呼びます。
そこで画像データを用いた機械学習では、もとの画像にランダムな変換を施して、さらに学習データを生成する「水増し」と呼ばれる手法が多く取り入れられています。

水増しには以下のような手法があります。
- rotation:回転
- width shifting:水平方向の移動
- height shifting:垂直方向の移動
- brightness:輝度の変更
- shear intensity:せん断
- zoom:拡大
- channel shift:色合い変更
- horizontal flip:水平方向の反転
- vertical flip:垂直方向の反転
OpenCVには、これらの画像の水増しや、以降で説明するエッジ抽出などを行う関数が豊富に用意されています。機械学習のKerasなどのライブラリにも画像の水増しを行う関数は用意されていますが、OpenCVの方がより高機能であり、実際のデータサイエンスの現場でも多く利用されています。
Lesson 8Chapter 1.5
OpenCVを使うための準備
OpenCVをPythonから利用するライブラリは、opencv-python です。ここではJupyterLabのノートブックのセルから
opencv-python をインストールします。
以下のようにセルへ入力し、実行してください。
!pip --no-cache-dir install opencv-python==4.4.0.44
以上でOpenCVのインストールは完了です。
Lesson 8Chapter 1.6
画像の読み込み
ライブラリの準備ができたら、OpenCVを使っていきましょう。まずは、画像を読み込んで、画面に表示してみましょう。
ライブラリのインポート
まずは、必要なライブラリをインポートします。
OpenCVは、cv2というライブラリ名です。すでに説明したように、OpenCVには画像の表示機能がありません。ここではグラフ表示ライブラリのmatplotlibを使って画像表示することにします。そこでこのライブラリもインポートしておきます。
下記で指定している%matplotlib
inlineは、matplotlibで表示する画像やグラフなどを別ウィンドウではなく、JupyterLab内部に表示するマジックコマンド(オプション)です。
また、ここでは画像を読み込んだあとに、さまざまな数値演算の加工をしますので、機械学習の基本的な数値演算ライブラリのNumpyもインポートしておきます。
# 各種インポート import cv2 import numpy as np import matplotlib.pyplot as plt %matplotlib inline
画像の読み込み
それでは画像を読み込んでみます。ここでは「東京タワーの画像」を使って演習します。
下記の画像yokto_tower.pngを右クリック→「名前を付けて保存」(ファイル名はtokyo_tower.pngのままにしてください)して、JupyterLabのノートブックと同じディレクトリに置いてください。

この画像は 横のサイズ:500, 縦のサイズ:750(単位:ピクセル(px))です。
画像を読み込むには、imreadを使います。OpenCVでは、読み込んだ画像はNumpyのndarray型になります(あとで見ていきますが、この配列に対してさまざまな演算処理をすることで画像を加工できます)。ndarray型になっていることは、type関数で確認できます。
# 画像の読み込み tokyo_tower = cv2.imread('tokyo_tower.png') print(type(tokyo_tower))
出力結果:
<class 'numpy.ndarray'>
画像の表示
読み込んだndarray型の画像は、matplotlibのimshow()で表示できます。表示した画像は実寸ではなく、画面に収まるように縮小表示されます。左と下には画像サイズを示すゲージが表示されます。
# ひとまず画像を表示してみる(間違い。色合いがおかしい)
plt.imshow(tokyo_tower)
しかし実際実行してみるとわかりますが、色がオリジナルと違ったものになってしまいます。

BGRをRGBに変換する
これはOpenCVの仕様によるものです。
OpenCVでimreadを使って読み込む場合、既定では、画像を「BGR」(青・緑・赤)の順の配列として読み込みます。対して、表示するためのmatplotlib.imshow()では、画像が「RGB」(赤・緑・青)の順の配列として構成されていることを前提としています。そのため、このまま表示すると、青と赤が入れ替わってしまうため、先に表示したように色がおかしくなってしまうのです。
そこで表示する前に、「BGR」から「RGB」に変換します。変換には、cvtColor()を使います。なお、cvtColor()について詳しくはChapter
2.3で後述します。
# BGRの画像をRGBに変換
rgb_tower = cv2.cvtColor(tokyo_tower, cv2.COLOR_BGR2RGB)
この変換後のデータを表示すれば、色合いが正しく表示されます。
# RGB形式の画像を表示
plt.imshow(rgb_tower)
出力結果:

Lesson 8Chapter 1.7
グレースケール変換
画像をグレースケールで扱うには、2つの方法があります。どちらの場合も結果は同じです。
-
グレースケールとして読み込む
ひとつめの方法は、
imread()で読み込むときに、オプションIMREAD_GRAYSCALEを指定します。# グレースケールで読み込む gray_tower = cv2.imread('tokyo_tower.png', cv2.IMREAD_GRAYSCALE)
-
読み込んでから変換する
もうひとつの方法は、読み込んだ後に、cvtColorで変換します。# すでに読み込んだものをグレースケール化する gray_tower02 = cv2.cvtColor(tokyo_tower, cv2.COLOR_BGR2GRAY)
グレースケール画像の表示
グレースケールに変換した画像を表示するには、カラー画像のときと同じくimshow()を使いますが、そのままだと、色合いが正しく表示されません。
plt.imshow(gray_tower)
出力結果:

これは、matplotlibの既定のカラーマップ設定によるものです。既定では、グレースケール画像の場合、色味が暗いほど青く、明るくなるにつれて 青 → 緑 → 黄色
の色味で表示されるという設定になっています。
そのため、JupyterLabで正しく 黒 → グレー → 白 の色味でモノクロ画像を表示するには、imshow() に、黒 → グレー
→ 白 の色味で表示できるよう、カラーマップの設定を追加する必要があります。具体的なコードの記述方法としては、 imshow() に
cmap="gray" というキーワード引数を追記します。
plt.imshow(gray_tower, cmap='gray')
出力結果:

Lesson 8Chapter 1.8
画像の保存
画像を保存するには、imwrite()を使います。引数には、対象の画像を読み込んだndarray配列とファイル名を順に指定します。たとえば、いまグレースケールに変換したgray_towerをtokyo_tower_gray.pngというファイル名で保存するには、次のようにします。
cv2.imwrite('tokyo_tower_gray.png', gray_tower)
出力結果:
True
これでグレースケールの東京タワーの写真(tokyo_tower_gray.png)が tokyo_tower.png と同じディレクトリに保存されました。

なおカラー画像を保存する場合は、表示するときと違って、BRGのままとします。つまり、先ほど読み込んだカラー画像tokyo_towerを、tokyo_tower_copy.pngという名前で保存するには、次のようにします。
正しい保存方法(BRG形式のまま保存する:
cv2.imwrite('tokyo_tower_copy.png', tokyo_tower)
保存されたtokyo_tower_copy.png:

間違って、次のようにRGB変換した後のrgb_towerを保存してしまうと、色合いが違ってしまうので注意してください。
間違った保存方法(RGB形式に変換した後のデータを保存する:
cv2.imwrite('tokyo_tower_copy_ng.png', rgb_tower)
保存されたtokyo_tower_copy_ng.png:

Lesson 8Chapter 1.9
アフィン変換 ~ 拡大縮小や回転、平行移動
画像の拡大縮小や回転、平行移動を行うにはアフィン変換と呼ばれる手法が広く使われています。ここで使い方について学びましょう。
アフィン変換とは
アフィン変換とは、座標(ベクトル)と行列を掛け合わせることで、画像の拡大縮小や回転、平行移動を行う変換のことです。拡大縮小や回転のことを「線形変換」と呼びます。線形変換には「拡大、縮小、剪断(四角形を平行四辺形に変形すること)、回転」などがあります。言い換えるとアフィン変換は「線形変換と平行移動を組み合わせた変換」ということになります。
もとの座標を$(x, y)$ 、変換後の座標を$(x’, y’)$とするとアフィン変換の式は以下で定義されます。
$a,b,c,d$が線形変換、$t_x,t_y$は平行移動を行います。また、$a, b, t_x$がx方向に関する要素、$c, d, t_y$はy方向に関する要素となります。計算結果は以下のようになります。
$t_x$と$t_y$を加算する部分を行列にまとめると1度に計算できて便利です。式を1つの行列の計算にまとめることを「同次変換」と呼びます。上記の式を同次変換すると以下のようになります。
計算結果は以下のようになります。先ほどと同様の結果が1回の行列の計算で得られることが分かります(3つ目の計算結果で得られる1=1は自明のため掲載を省略しています)。この同次変換後の行列を「変換行列」と呼びます。以降はこの変換行列を使用します。
それでは具体的なアフィン変換のパターンを確認しながら、変換行列のどの部分が、アフィン変換する際の何に相当しているのか確認していきましょう。
拡大・縮小
x軸方向の拡大縮小率を$S_x$、y軸方向の拡大縮小率を$S_y$とすると、拡大縮小率を行うアフィン変換は以下のようになります。
計算結果は以下のようになります。
平行移動
x軸方向の移動量を$T_x$、y軸方向の移動量を$T_y$とすると、平行移動を行うアフィン変換は以下のようになります。
計算結果は以下のようになります。
回転
回転には三角関数の知識が必要となります。OpenCVには回転用の変換行列を求める関数があるため、この変換行列を覚える必要はありません。原点を中心として反時計回りに$\theta$度回転させるアフィン変換は以下のようになります。
計算結果は以下のようになります。
OpenCVでアフィン変換を行う方法
OpenCVでアフィン変換を行うには warpAffine() 関数を使います。warpAffine() 関数の書き方は以下のとおりです。
出力画像 = cv2.warpAffine(もとの画像, 変換行列, 出力画像サイズ)
変換行列は2行3列の大きさで指定します。前述の通り変換行列は3行3列で指定しますが、3行目は[0,0,1]で自明のため指定する必要はありません。 warpAffine()
関数が内部で補ってくれます。
拡大縮小
それでは実際にアフィン変換を行ってみましょう。はじめは拡大縮小です。拡大縮小を行う変換行列を再掲します。
これをPythonで記述します。変換行列は2行3列の大きさで指定します。
# 画像の拡大縮小(横に50%, 縦に150%) M = np.float32([[0.5, 0, 0], [0, 1.5, 0]])
warpAffine() 関数でアフィン変換を行います。最後の引数の出力画像サイズには(幅$=500 \times 0.5=250$, 高さ$=750 \times
1.5=1125$)を指定します。
# 引数の最後は出力する画像サイズ tokyo_tower_resized = cv2.warpAffine(tokyo_tower, M, (250, 1125))
これで拡大縮小した画像が、tokyo_tower_resizedに格納されました。imshowで表示すると、次のように、幅を縮小し、高さを拡大した画像に変換されたことがわかります。
# 拡大縮小した画像を表示
plt.imshow(cv2.cvtColor(tokyo_tower_resized, cv2.COLOR_BGR2RGB))

resize()関数
単に拡大縮小を行うだけであればresize()関数を使ってもかまいません。引数には変換後の (画像の横のサイズ, 画像の縦のサイズ)
を指定します。今回は縦横50%に縮小してみます。指定したサイズに変換されたかどうかを、画像の左や下に表示されるゲージで確認しておきましょう。
# 画像のリサイズ tokyo_tower_resized2 = cv2.resize(tokyo_tower, (250, 375)) # リサイズした画像を表示 plt.imshow(cv2.cvtColor(tokyo_tower_resized2, cv2.COLOR_BGR2RGB))
出力結果:

平行移動
つぎは平行移動です。平行移動を行う変換行列を再掲します。
先ほどと同様にPythonで記述しましょう。今回はx軸方向に100、y軸方向に50移動します。
# 画像の平行移動(横に100, 縦に50) M = np.float32([[1, 0, 100], [0, 1, 50]])
warpAffine() 関数でアフィン変換を行います。出力画像サイズは変わらないため(500, 700)を指定します。
# 引数の最後は出力する画像サイズ tokyo_tower_translated = cv2.warpAffine(tokyo_tower, M, (500, 750))
これで平行移動した画像が、tokyo_tower_translatedに格納されました。imshowで表示すると、次のように、横に100、縦に50だけ移動した画像に変換されたことがわかります。
# 平行移動した画像を表示
plt.imshow(cv2.cvtColor(tokyo_tower_translated, cv2.COLOR_BGR2RGB))
元の画像サイズと同じ大きさで出力する
上の例では出力する画像サイズを(500,
700)という固定値にしていますが、元の画像サイズと同じサイズにしたいということもあるでしょう。元の画像サイズは、次のようにshapeで求めることができます(データ構造については、このチャプターの最後で改めて説明します)。求められる値は、順に「高さ」「幅」「色数」です。
h, w, c = tokyo_tower.shape
このようにしてあらかじめ「高さh」「幅w」を求めておき、次のようにすれば、固定値ではなく元の画像の大きさに合わせて、それと同じ大きさにできます。
tokyo_tower_translated = cv2.warpAffine(tokyo_tower, M, (w, h))
結果は先ほどと同様です。
plt.imshow(cv2.cvtColor(tokyo_tower_translated, cv2.COLOR_BGR2RGB))
回転
つぎは回転です。回転を行う変換行列を再掲します。
この行列を自分で求めるのは大変です。幸いなことにOpenCVには回転を行う変換行列を求める getRotateMatrix2D()
関数が用意されています。getRotateMatrix2D() 関数の使い方は以下のとおりです。
getRotateMatrix2D(回転の中心座標, 回転角度, 拡大比率)`
回転角度は反時計回りで指定します。たとえば回転の中心座標を画像の中心とし、90度回転させるための行列Mは、次のようにして求めることができます。画像の中心は元の画像サイズから求めています。
# 回転の中心座標を画像の中心とし、反時計回りに90度回転させるための行列を求める h, w, c = tokyo_tower.shape M = cv2.getRotationMatrix2D((w/2, h/2), 90, 1)
warpAffine() 関数でアフィン変換を行います。ここでは変換後の出力画像サイズを(750, 750)としました。
# 求めた回転行列でアフィン変換する tokyo_tower_rotated = cv2.warpAffine(tokyo_tower, M, (750, 750))
表示した結果は、次の通りです。
# 回転した画像を表示
plt.imshow(cv2.cvtColor(tokyo_tower_rotated, cv2.COLOR_BGR2RGB))
出力結果:

縦横を保ったまま回転する
上記の結果を見るとわかりますが、回転した画像の左が切れて、余白(黒い部分)が付いています。これは回転させた画像が、元のサイズよりも大きくなるため、左が切り取られてしまうからです。

このようにならないようにするには、回転しても収まる場所に平行移動してから回転します。
下図のように、まず表示領域を(750, 750)にし、左に125だけズラすことで、画像を表示領域の中心に配置します。
それから反時計回りに90度回転させます。すると画像は切れませんが、上下に余白ができます。
そこで最後にこの余白を切り取るため、上に125だけ移動し、表示領域を(750, 500)に縮めます。こうすれば切れてしまうことはありません。

実際にこの処理をPythonで記述したものを、以下に示します。各種サイズは元の画像サイズから求めています。このように画像サイズを変数に保持して処理を行うようにすると、画像サイズが変わった場合でもプログラムを変更する必要がなくなります。
# 元の画像サイズを取得 h, w, c = tokyo_tower.shape # ①125だけ左に移動、表示領域を(750, 750)=(h, h)に広げる M1 = np.float32([[1, 0, 125], [0, 1, 0]]) tokyo_tower_tr1 = cv2.warpAffine(tokyo_tower, M1, (h, h)) # ②中心点は(375, 375)=(w/2+125, h/2)で、反時計回りに90度回転 M2 = cv2.getRotationMatrix2D((w/2+125, h/2), 90, 1) # 出力画像サイズは(750, 750)=(h, h) tokyo_tower_tr2 = cv2.warpAffine(tokyo_tower_tr1, M2, (h, h)) # ③上に125(縦方向に-125)移動。表示領域を(750,500)=(h, w)にする M3 = np.float32([[1, 0, 0], [0, 1, -125]]) tokyo_tower_tr3 = cv2.warpAffine(tokyo_tower_tr2, M3, (h, w)) # 平行移動と回転をさせた画像を表示 plt.imshow(cv2.cvtColor(tokyo_tower_tr3, cv2.COLOR_BGR2RGB))
出力結果:

回転した画像を保存する
最後に、この回転した画像を保存しておきましょう。imwriteを使って、tokyo_tower_tr.pngという名前で保存してみます。
# 90度回転した画像を保存 cv2.imwrite('tokyo_tower_tr.png', tokyo_tower_tr3)
画像の反転
cv2.flipを使うと、画像を反転できます。反転方向は、引数で指定します。
| 引数に指定する値 | 反転方向 |
|---|---|
| 0 | 上下反転 |
| 1 | 左右反転 |
| -1 | 上下左右反転 |
-
上下反転の例
# 上下反転 tokyo_tower_ud = cv2.flip(tokyo_tower, 0) # 反転させた画像を表示 plt.imshow(cv2.cvtColor(tokyo_tower_ud, cv2.COLOR_BGR2RGB))
出力結果:

-
左右反転の例
# 左右反転 tokyo_tower_lr = cv2.flip(tokyo_tower, 1) # 反転させた画像を表示 plt.imshow(cv2.cvtColor(tokyo_tower_lr, cv2.COLOR_BGR2RGB))
出力結果:

-
上下左右反転の例
# 上下も左右も反転 tokyo_tower_udlr = cv2.flip(tokyo_tower, -1) # 反転させた画像を表示 plt.imshow(cv2.cvtColor(tokyo_tower_udlr, cv2.COLOR_BGR2RGB))
出力結果:

一括処理
画像の水増し処理を任意のフォルダにあるすべての画像に対して一括して行うことも可能です。ここでその方法について確認しましょう。
以下のリンクをクリックしてファイルをダウンロードします。解凍してできたimagesフォルダをノートブックと同じ場所にコピーしておきます。
フォルダには以下の3枚の画像が入っています。

まずは必要なライブラリをインポートします。共にファイル操作で使用するライブラリです。
import os import glob
条件に合致するすべてのファイルを取得します。結果はファイル名のリストとして返ります。
# glob.glob:条件に合致するすべてのファイルを取得 files = glob.glob('./images/*.JPG') files
出力結果:
['./images\\fish1.JPG', './images\\fish2.JPG', './images\\fish3.JPG']
変換行列を用意します。今回は画像を縦横半分に縮小することとします。
# 変換行列の定義:画像の拡大縮小(横に50%, 縦に50%) M = np.float32([[0.5, 0, 0], [0, 0.5, 0]])
ファイル名のリストをfor文で繰り返し処理しながらアフィン変換を行っていきます。
# 変換行列の定義:画像の拡大縮小(横に50%, 縦に50%) M = np.float32([[0.5, 0, 0], [0, 0.5, 0]]) # 半分のサイズにリサイズし、ファイル名にhalfを付けて保存する for f in files: # 画像の読込 img = cv2.imread(f) # 形状を取得 h, w, c = img.shape # 変換行列の適用 img_resized = cv2.warpAffine(img, M, (w//2, h//2)) # ファイル名と拡張子の分離 title, ext = os.path.splitext(f) # ファイル名にhalfを付けて保存 cv2.imwrite(title + '_half' + ext, img_resized)
出力結果:
imagesフォルダに、ファイル名にhalfが付いた半分の大きさの画像が保存されていることを確認しましょう。

Lesson 8Chapter 1.10
OpenCVとndarrayとの関係
OpenCVは、読み込んだ画像をNumPyの配列であるndarrayで保持しています。この配列の中身を見れば、RGBの濃度を調べたり、画像に加工したりできます。ここではndarrayの構造と操作について簡単に説明します。
データの形式とピクセルの値の抽出
OpenCVで読み込んだデータであるndarrayは、左上から右下に向けて、1ピクセルずつBGR(青、緑、赤)の色の強さが0~255までの256段階の値として格納された構造です。
ndarrayのプロパティshapeを調べると、配列の要素数がわかるので、確認してみましょう。まずはカラー画像として読み込んだtokyo_towerを調べてみます。
print(tokyo_tower.shape)
出力結果:
(750, 500, 3)
750, 500 というのは、画像の縦のサイズ(750px)と横のサイズ(500px)です。つまり「画像の高さ分の行 ×
画像の幅分の列」というサイズの2次元配列として構成されています。
最後の 3 は 750 * 500 の2次元配列を3個持っている、という意味です。この 3
について具体的に言うと、BGR(青緑赤) それぞれについての、色の強さ(濃さ)に関する情報です。配列は0から数えますので、750 * 500
の2次元配列の0番目が青、1番目が緑、2番目が赤の配列ということになります。図で表すと以下のようになります。

試しに左上の端にあるピクセル(横と縦の座標が0のピクセル)の情報を見てみましょう。スライスを使います。3番目にコロン(:)のみを指定することで、青・緑・赤のすべての色の情報を取得できます。
print(tokyo_tower[0, 0, :])
出力結果:
[218 166 116]
出力結果の情報は B(青), G(緑),R(赤) の順でならんでいます。つまり、これは左上のピクセルが、青 218・緑
166・赤 116 の色の強さで構成されているということを示しています。
cvtColorでCOLOR_BGR2RGBを指定してRGBに変換した後は、RGB(赤、緑、青)の順になります。
またたとえば、すべてのピクセルにおいてR(赤)の情報のみを取得したい場合は、以下のようにスライスします。画像のピクセルは、B=0、G=1、R=2の順で並んでいるので、最後の引数に2を指定すれば、赤のみの情報を取得できます。
# 赤のみのピクセル情報を取得 print(tokyo_tower[:, :, 2])
出力結果:
[[116 119 120 ... 86 88 89]
[119 117 118 ... 89 85 87]
[121 116 118 ... 87 87 90]
...
[193 190 164 ... 29 24 17]
[156 171 147 ... 29 25 16]
[157 146 149 ... 29 28 19]]
グレースケールの場合のデータ形式
グレースケールの場合は、BGRのそれぞれの要素ではなく、白と黒のみの濃さとして0(黒)~255(白)の値で構成されます。確認してみましょう。
このレッスンのはじめのほうで、imreadで画像を読み取る際に、IMREAD_GRAYSCALEを指定してグレースケールに変換して読み込んだgray_towerがあります。これについて、shapeで確認してみます。
# グレースケールデータの形式
print(gray_tower.shape)
出力結果:
(750, 500)
結果を見るとわかるように、最後の 3
がなくなっています。左上のピクセルの濃度を次のようにスライスして確認しましょう。カラー画像と違って、RGBの各要素はなく、単一の0~255の値として構成されることがわかります。
print(gray_tower[0, 0])
出力結果:
156
nparrayを使ったデータ操作の例
このようにOpenCVは、画像データをndarray 形式として持っているため、数値計算による画像加工が可能になります。
機械学習における「画像の分類」は、ピクセルの情報を数値化したものを基にして判断しています。*先ほど説明したカラー画像とモノクロ画像での ndarray
の構造は、ぜひ理解しておいてください。
ここで簡単な例として、画像の濃度(濃さ)を半分にするという例を示します。すでに説明したように、ndarray配列のそれぞれの要素は、BGRの濃度です。そこでたとえば次のようにすれば、濃度を半分(半分の濃さ)に変換し、それを表示できます。実行例を見るとわかるように、画像が暗く表示されます。
// は整数の割り算をする演算子で、割り算の結果の小数以下を切り捨てます。
# カラーデータの濃度を半分にして表示 half_tower = tokyo_tower // 2 plt.imshow(cv2.cvtColor(half_tower, cv2.COLOR_BGR2RGB))
出力結果:

Lesson 8Chapter 1.11
ここまでのまとめ
このチャプターでは、OpenCVを使った基本的な画像操作を説明しました。
画像はimreadで読み込みますが、このときBGR形式なので、matplotlibで表示する場合には、cvColorでCOLOR_BGR2RGBを指定してRGB形式に変換しなければなりません。グレースケールで読み込むには、読み込む際にIMREAD_GRAYSCALEを指定します。
画像の平行移動や回転には、wrapAffineを使います。回転するときは切れないように表示領域を広げたり、移動してから回転するなどの工夫が必要です。
Lesson
8Chapter 2
OpenCVを使った応用的な画像加工
Lesson 8Chapter 2.1
はじめに
このチャプターでは、色変換や画像の切り抜き、重ね合わせなど、画像を加工するさまざまな方法を習得します。
Lesson 8Chapter 2.2
対象画像の読み込み
このチャプターでは、以下のロケットの写真画像を利用します。この写真を右クリック→「名前をつけて保存」(ファイル名は H2A.jpg のままで保存)して、JupyterLabのノートブックと同じディレクトリに置いてください。

この画像は 横のサイズ:500, 縦のサイズ:750(単位:ピクセル(px))です。
画像の読み込み
前までのチャプターで行ったように、cv2.imreadを使って読み込みます。ここでは読み込んだ画像をrocket_orgという変数に保存します。そしてmatplotlibのimshowを使って表示します。BGR形式からRGB形式に変換しないと、正しい色で表示されないというのは、今まで説明した通りです。
# 画像の読み込み rocket_org = cv2.imread('H2A.jpg') # 画像の表示 plt.imshow(cv2.cvtColor(rocket_org, cv2.COLOR_BGR2RGB))
出力結果:

画像サイズと形式の確認
読み込んだ画像はndarray形式です。shapeで縦横のサイズと色数を確認しておきます。
# 画像のサイズを取得(縦1067, 横800のBGR形式(3色))
rocket_org_height, rocket_org_width, rocket_org_colornum = rocket_org.shape
print(rocket_org_height) print(rocket_org_width) print(rocket_org_colornum)
出力結果:
1067
800
3
Lesson 8Chapter 2.3
色空間の変換
色は、光の三原色である「R(赤)」「G(緑)」「B(青)」の組み合わせで表現する以外にも、「色相」「彩度」「明度」で表現するHSV形式や、人間の目の視覚特性で表現するCIE XYZ形式など多くの形式があります。こうした表現形式を「色空間」と言います。
OpenCVでは、cv2.cvtColor(画像データ, cv2.○○○)を使うことで、色空間を変換できます。グレースケールに変換する機能もあります。
https://docs.opencv.org/4.4.0/d8/d01/group__imgproc__color__conversions.html
主な変換定数
| 変換の定数 | 意味 |
|---|---|
| cv2.COLOR_BGR2RGB | BGR形式からRGB形式へ |
| cv2.COLOR_RGB2BGR | RGB形式からBGR形式へ |
| cv2.COLOR_BGR2HSV | BGR形式からHSV形式へ |
| cv2.COLOR_RGB2HSV | RGB形式からHSV形式へ |
| cv2.COLOR_BGR2GRAY | BGR形式からグレースケールへ |
| cv2.COLOR_RGB2GRAY | RGB形式からグレースケールへ |
| cv2.CLOLR_HSV2GRAY | HSV形式からせグレースケールへ |
たとえば次のようにすると、BGR形式(これは既定の形式です)を、HSV形式という「色相」「彩度」「明度」で表現する方式に変換できます。
「3.2.3 OpenCVの発展的な画像加工」で説明しますが、HSV形式では「色相」が、「青系」「赤系」「黄色系」などの色合いごとに近い値となるため、特定の色合いの部分を抽出しやすいなどの特徴があります。
# HSV形式へ変換する
rocket_hsv = cv2.cvtColor(rocket_org, cv2.COLOR_BGR2HSV)
Lesson 8Chapter 2.4
画像の連結
画像を縦や横の連結するには、次のようにします。まずは連結用の画像を1枚用意しましょう。
# 連結用に、カラーデータの濃度を1/3にした画像を用意 rocket_half = rocket_org // 3 plt.imshow(cv2.cvtColor(rocket_half, cv2.COLOR_BGR2RGB))
-
縦に連結
cv2.vconcat()を使います。# 画像を縦に連結 rocket_vconcat = cv2.vconcat([rocket_org, rocket_half]) # 画像の表示 plt.imshow(cv2.cvtColor(rocket_vconcat, cv2.COLOR_BGR2RGB))
出力結果:

-
横に連結
cv.hconcat()を使います。# 画像を横に連結 rocket_hconcat = cv2.hconcat([rocket_org, rocket_half]) # 画像の表示 plt.imshow(cv2.cvtColor(rocket_hconcat, cv2.COLOR_BGR2RGB))
出力結果:

Lesson 8Chapter 2.5
画像の切り抜きと分割
画像の一部を切り抜くには、ndarrayをスライスとして操作します。
座標を指定した単純な切り抜き
たとえば次のようにすると、(200, 400)から(650, 500)の範囲を取り出せます。
図に示したように、最初の引数がY座標、次の引数がX座標です。Pythonのスライス操作で指定する終点は、その値を含まないため、1つ大きな値を指定する点に注意してください。

# ロケットの部分の切り抜き rocket_crop = rocket_org[200:651, 400:501, :] # 切り抜いた画像の表示 plt.imshow(cv2.cvtColor(rocket_crop, cv2.COLOR_BGR2RGB))
出力結果

画像の分割
ndarrayを分割することで、画像を縦横に分割できます。たとえば次のようにすると、縦方向に200pxずつに輪切りにした4つの画像を作ることができます。

# 画像を縦200pxずつに区切った画像(800pxまでの4枚分)へ分割 rocket_crop_list = [] for i in range(4): rocket_crop = rocket_org[200*i:200*(i+1), :, :] rocket_crop_list.append(rocket_crop) # 下端の画像のみ表示 plt.imshow(cv2.cvtColor(rocket_crop_list[3], cv2.COLOR_BGR2RGB))
出力結果

Lesson 8Chapter 2.6
GIFアニメーションとして保存
画像をGIFアニメーションにすることもできます。これはOpenCVではできないので、Matplotlib.animationを使います。
# 必要なライブラリのインポート import matplotlib.animation as animation
※ほかの方法としてPandasライブラリを使う方法もありますが、ここでは省略します。
Lesson 8Chapter 2.7
GIFアニメーションを作る例
まず実際にGIFアニメーションを作る例を示します。ここでは、いま4つに分割したrocket_crop_list[0]~rocket_crop_list[3]をGIFアニメーションを作成してみます。
次のプログラムを実行すると、rocket_anim.gifという画像ファイルを作られます。ダブルクリックするとブラウザで開くことができ、アニメーションすることがわかるはずです。
# 画像に関する事前設定 fig = plt.figure(figsize=(4,1), dpi=200) # これで横800px, 縦200pxのGIF画像になる ax = fig.add_axes([0, 0, 1, 1]) # 余白なしにする ax.axis('off') # グラフの軸やタイトルといった要素を非表示にする # 4分割にした画像それぞれをRGB形式にして新しいリスト(rocket_crop_gif_list)に入れる rocket_crop_gif_list = [] for i in range(4): rocket_crop_gif = ax.imshow(cv2.cvtColor(rocket_crop_list[i], cv2.COLOR_BGR2RGB)) rocket_crop_gif_list.append([rocket_crop_gif]) # アニメーションの作成 anim = animation.ArtistAnimation(fig, rocket_crop_gif_list, interval=500, repeat_delay=500) # GIF画像として保存(内部的にPillowの機能を使うようwriterで設定) anim.save('rocket_anim.gif', writer='pillow')
※上記のプログラムではmatplotlibでまず、同サイズの白い画像を作って、そこにアニメーション画像を書き出しています。そのため実行するとJ、JupyterLabのノートブックの画面には、その白い画像が表示されますが、気にしないでください。
作成したアニメーション画像

アニメーションの作り方
作成したプログラムを簡単に解説します。アニメーションを作るのにあたり、まずは、画像を作成します。それにはplt.figureを使います。書式は、次の通りです。
画像変数 = plt.figure(figsize=(横インチ, 縦インチ), dpi=解像度)
単位でインチであるので少しわかりにくいのですが、先のプログラムでは、plt.figure(figsize=(4,1),
dpi=200)としています。解像度は1インチ当たりのピクセル数です。ですから、4×200=800px、1×200=200pxの画像として作成されます。
もちろんこの部分は、plt.figure(figsize=(8,2), dpi=100)などのようにしても結果は同じです。
matplotlibでは、既定で左と下に余白があり、軸のゲージが表示されるので、余白をナシにして軸のゲージを非表示にしておきます。
ax = fig.add_axes([0, 0, 1, 1]) # 余白なしにする ax.axis('off') # グラフの軸やタイトルといった要素を非表示にする
次に画像を分割して、(OpenCVのBGRではなくて)matplotlibで扱えるRGBの画像に変換しておきます。下記の処理で、rocket_crop_gif_listには、RGB形式に変換された画像が格納されます。
rocket_crop_gif_list = [] for i in range(4): rocket_crop_gif = ax.imshow(cv2.cvtColor(rocket_crop_list[i], cv2.COLOR_BGR2RGB)) rocket_crop_gif_list.append([rocket_crop_gif])
これで準備完了です。
animation.ArtistAnimationを使うとアニメーションを作れます。intervalはコマの表示時間(ミリ秒単位。1ミリ秒は1000分の1秒)、repeat_delayは繰り返し表示する際のループの先頭に戻る待ち時間(同じくミリ秒)です。ここでは500を指定し、0.5秒ごとにコマが変わるようにしました。
# アニメーションの作成 anim = animation.ArtistAnimation(fig, rocket_crop_gif_list, interval=500, repeat_delay=500)
最後に、作成したアニメーションを書き出します。
# GIF画像として保存(内部的にPillowの機能を使うようwriterで設定) anim.save('rocket_anim.gif', writer='pillow')
Lesson 8Chapter 2.8
単色化
カラー画像の場合、ndarrayの配列は、1ピクセルが「B(青)」「G(緑)」「R(赤)」の3要素で構成されているので、それぞれの要素だけを取り出せば、単色化できます。
青・緑・赤の原色をそれぞれ取り出す例
たとえば赤の情報だけを残したいのであれば、次のようにします。
- すべて初期値
0のndarray(元と同じ大きさ)を作成 - 元画像から赤のチャンネル(BGRの場合、要素の[2]に相当します)のデータをスライスして、上記1の配列に格納する
以下のサンプルは、青・緑・赤の単色化をし、それを先に説明したhconcatを使って横に並べる処理をするものです。
# 青のみの単色化 rocket_b = np.zeros((rocket_org_height, rocket_org_width, 3), dtype=np.uint8) rocket_b[:, :, 0] = rocket_org[:, :, 0] # 緑のみの単色化 rocket_g = np.zeros((rocket_org_height, rocket_org_width, 3), dtype=np.uint8) rocket_g[:, :, 1] = rocket_org[:, :, 1] # 赤のみの単色化 rocket_r = np.zeros((rocket_org_height, rocket_org_width, 3), dtype=np.uint8) rocket_r[:, :, 2] = rocket_org[:, :, 2] # 単色化した画像を横に並べて表示 rocket_monos = cv2.hconcat([rocket_b, rocket_g, rocket_r]) plt.imshow(cv2.cvtColor(rocket_monos, cv2.COLOR_BGR2RGB))
出力結果:

特定の原色を取り除く
青・緑・赤の原色要素のうち、特定の原色を取り除くこともできます。たとえば下記のプログラムは、青だけ抜いて、赤と緑要素のみの画像を作成します。
最初に画像と同じ大きさの全部が0に設定されたndarrayを作り、そこに緑の要素([1])と赤の要素([2])だけを設定します。
ここでは単純に抜いていますが、「青要素に0.3をかけて設定する」という処理にすれば、青色成分だけを30%にするといった、特定の原色の割合を下げるような処理もできます。
# 青だけ抜いた(赤と緑のみの)画像に加工 rocket_gr = np.zeros((rocket_org_height, rocket_org_width, 3), dtype=np.uint8) rocket_gr[:, :, 1] = rocket_org[:, :, 1] rocket_gr[:, :, 2] = rocket_org[:, :, 2] plt.imshow(cv2.cvtColor(rocket_gr, cv2.COLOR_BGR2RGB))
出力結果:

Lesson 8Chapter 2.9
2値化
基本的にBGR(RGBも同じ)やグレースケール画像は、256段階で色の強さを表します。対して2値化とは、画像を「0」(黒)と「1」(白)の2種類の値で表現する方法です。形や輪郭を抽出するなどの目的で、よく使われます。
色の強さを基準とした2値化
ある程度の色の強さを基準として2値化するには、グレースケール画像に変換したあと、その値がある値を超えたときは「1」、そうでなければ「0」になるように数値加工します。基準となる、ある値のことは、「しきい値」あるいは「閾値(いきち)」と呼ばれます。
たとえば次のようにすると、色の強さが128を超えたときに「1」となる画像を作成できます。演算子「//」は、小数点以下を切り捨てる割り算です。下記の例では、128で割り算していますから、128を超えていれば「1」、そうでなければ「0」に変換されます。
# 色の強さ 128 を基準とした2値化 rocket_gr = cv2.imread('H2A.jpg', cv2.IMREAD_GRAYSCALE) rocket_wb1 = rocket_gr // 128 plt.imshow(rocket_wb1, cmap="gray")
出力結果:

基準値を変えれば、白や黒の度合いが変わります。下記は、いま作成した128を基準とした2値化に加え、160を基準とした2値化、192を基準とした2値化の画像を作って横に並べることで、その違いを比較できるようにした例です。
# 色の強さ 160 を基準とした二値化 rocket_wb2 = rocket_gr // 160 # 色の強さ 192 を基準とした二値化 rocket_wb3 = rocket_gr // 192 # 二値化した画像を横に並べて表示 rocket_wbs = cv2.hconcat([rocket_wb1, rocket_wb2, rocket_wb3]) plt.imshow(rocket_wbs, cmap="gray")
出力結果

特定の濃度以上の部分だけを残す
2値化処理を応用することで、特定の色の強さ以上のピクセルデータを抽出できます。以下の手順で処理します。
- 特定の色のみのデータを用意する
- 2値化処理を実施し、各ピクセルの色の強さがある値以上かどうか調べる
- 1の配列と2の配列をかけ算する
2値化した配列は0か1しか含まれていません。この配列を元の画像データとかけ算することで、2値化した配列のピクセルが 0
の部分に対応する画像データのピクセルは、かけ算により 0 となります。また、2値化した配列のピクセルが 1
の場合は、元の画像データの数値がそのまま残ります。このような計算により、特定の色の強さ以上のピクセルデータを抽出できます。

下記の例は、赤の要素に対して、240以上のところだけを残し、それ以外は取り去る処理を施した例です。元の画像の赤が濃い部分だけが抽出されていることがわかります。
# 赤のみの画像データの元(rocket_r)を変更しないよう、複製物の作成 rocket_r_trimmed = np.copy(rocket_r) # 赤の色について、色の強さ 240 を基準とした二値化 rocket_r_wb = rocket_r_trimmed[:, :, 2] // 240 # 赤のみの画像データと二値化したデータのかけ算 rocket_r_trimmed[:, :, 2] *= rocket_r_wb # 赤の強さ 240 以上のみのピクセルを残した画像データの表示 plt.imshow(cv2.cvtColor(rocket_r_trimmed, cv2.COLOR_BGR2RGB))
出力結果:

Lesson 8Chapter 2.10
特定の条件を満たす部分をマスキング
元の画像から、いま抜き出した赤い領域の部分だけをくりぬいた画像を作成してみましょう。このような処理は「マスキング」と言います。

OpenCVでは、cv2.bitwise_and()を使うことで、画像同士のビット単位の論理積演算(AND演算)ができます。
ビット単位の演算についての詳細は省きますが、マスキングする場合は、「0」と「255」のいずれかの値で構成されるndarrayを用意しておいてcv2.bitwise_and()を実行すると、255の部分だけが抜き出され、0の部分は除去されるという性質があります。
そこで下図のように、先ほど作成しておいた赤が240を超えたかどうかという条件で2値化したデータを255倍することで「0」と「255」のマスキング用のndarrayを作ります。元画像に対して、このマスキングのndarrayをcv2.bitwise_and()で計算すると、その部分だけが抜き出されます。

実際にやってみましょう。まずは、マスク画像を作成します。
# マスキング用のデータ(すべて0で初期化) rocket_trimmed_img = np.zeros((rocket_org_height, rocket_org_width, 3), dtype=np.uint8) # BGRすべてで、2値化されたものを「0」と「255」に変換したもの for i in range(3): rocket_trimmed_img[:, :, i] = rocket_r_wb * 255 # マスク画像を表示 plt.imshow(cv2.cvtColor(rocket_trimmed_img, cv2.COLOR_BGR2RGB))
出力結果:

こうして作成したマスク画像を使って、cv2.bitwise_andを使えば、くりぬいた画像を作成できます。
# マスク処理を実行して結果を表示
rocket_masked = cv2.bitwise_and(rocket_org, rocket_trimmed_img)
plt.imshow(cv2.cvtColor(rocket_masked, cv2.COLOR_BGR2RGB))
出力結果:

Lesson 8Chapter 2.11
画像の重ね合わせ
最後に、異なる2つの画像を重ね合わせる方法を紹介します。ここではhome1.pngとhome2.pngという2つの画像を扱います。下記からダウンロードしてください。
ファイルを展開し、JupyterLabのノートブックと同じフォルダに配置してください。それぞれ読み込んで内容を確認してみましょう。
# home1.png画像の読み込み im1 = cv2.imread('home1.png') # 画像の表示 plt.imshow(cv2.cvtColor(im1, cv2.COLOR_BGR2RGB))
出力結果:

# home2.png画像の読み込み im2 = cv2.imread('home2.png') # 画像の表示 plt.imshow(cv2.cvtColor(im2, cv2.COLOR_BGR2RGB))
出力結果:

どちらも似たような画像ですが、home1.pngは壁だけ、home2.pngは壁に青い風船が写った画像です。以下の操作では、この2つの画像を重ね合わせてみます。
単純な引き算
まずは、単純な引き算をしてみます。home1.pngとhome2.pngの違いは青い風船の部分だけなので、引き算すれば、その違いである青い風船部分が際立って見えるはずです。
# 単純に画像を引き算したものを表示
plt.imshow(cv2.cvtColor((im2 - im1), cv2.COLOR_BGR2RGB))
出力結果:

実際にやってみると、予想通り、青い風船の部分だけが浮かび上がってきました。風船の色も一部が緑色になったりしていますが、風船のみがはっきりと見え、背景部分はほぼ真っ黒です。このように、単純な引き算により、「ある程度は」画像内の差分の部分を抽出できます。
「ある程度は」と書いたのは、撮影時のタイミングにおける光の誤差の影響などでノイズが残ってしまっているからです。きれいに風船のみを抽出するためにはノイズを除去する必要がありますが、単純な引き算だけでは限界があります。ノイズを除去する方法については後述します。
cv2.addWeighted()
cv2.addWeighted()を使うと、2つの画像の透明度を調整して重ね合わせることができます。この重ね合わせ方法は、アルファブレンドとも呼ばれ、次の書式をとります。
結果 = cv2.addWeighted(画像1, 画像1の透明度, 画像2, 画像2の透明度, ガンマ補正値)
透明度は0~1までの値で、0が透明、1に近づくほど不透明です。ガンマ補正値とは色の補正をするための設定です。詳しくは「3.2.4 OpenCVを用いた地理空間情報解析」で説明します。補正の必要がないときは0を指定します。
たとえば2つの画像を透明度0.7、透明度0.3で、それぞれ重ね合わせるときは、次のようにします。
# addWeighted()を利用して重ね合わせる im3 = cv2.addWeighted(im1, 0.7, im2, 0.3, 0) # 重ね合わせた画像の表示 plt.imshow(cv2.cvtColor(im3, cv2.COLOR_BGR2RGB))
出力結果:

Lesson 8Chapter 2.12
ここまでのまとめ
このチャプターでは、OpenCVを使った基本的な画像の加工方法を説明しました。OpenCVにおける画像は、ndarrayとして青・緑・赤の原色が0~255の範囲の値で格納されています。ですから、画像の一部を取り出したいのなら、ndarrayに対してスライス操作すればよく、濃度を変えたいのなら値をかけ算します。
また特定の値より小さいか大きいかによって0、1のいずれかの値に変換する2値化は、画像から特定部分だけを描画するマスク処理の基本的な考え方です。
Lesson
8Chapter 3
OpenCVの発展的な画像加工
Lesson 8Chapter 3.1
学習の目標
このチャプターでは、画像の輪郭抽出やマーキング、畳み込みやノイズ除去など、高度な画像加工方法を習得します。
Lesson 8Chapter 3.2
HSV色空間に関する処理
画像を光の三原色である「青(B)」「緑(G)」「赤(R)」の要素で表現する方法は一般的ですが、この表現方法は、「色合いが同じかどうか」「明るさが同じかどうか」を判別するのが少し困難です。そこで用途によっては、別の色の表し方を使うことがあります。よく使う別の方法が、HSV色空間です。
HSV色空間の基礎
HSV色空間は、「色相(H)」「彩度(S)」「V(明度)」の3つの軸で色を表現する方法です。
- 色相(Hue)
赤系統・黄色系統・緑系統・青系統など、どのような色合いかを示す値です。HSV色空間は一般に円を一周ぐるりと回るように、色合いの近いもの同士が配置された配列になっており、値の範囲を、その角度に相当する0~360の範囲で扱います。OpenCVで扱う場合は、この値を2で割って整数にした0~179の範囲で扱います。 - 彩度(Saturation)
色の鮮やかさや濃さに相当する値です。OpenCVでは0~255までの整数で示します。値が大きいほど鮮やかで、0に近いほど灰色っぽくなります。 - 明度(Value)
明るさを示します。OpenCVでは0~255までの整数で示し、0に近いほど暗く(黒く)、255に近いほど明るく(原色に近く)なります。
言葉で説明しても難しいので、色相を0~179までの範囲で変えたものをグラフ表示するプログラムを示します。
OpenCVでHSV形式を扱うときもBGR形式同じくndarrayです。[0]が色相、[1]は彩度、[2]が明度に相当します。このようなデータを作っておき、cv2.cvtColorにcv2.CLOLR_HSV2BGRという定数を指定することで、BGR形式に変換します(matplotlibで表示する際には、さらにRGBに変換します)。
# H(色相)の値と色の関係をグラフに表示 h_map = np.zeros((60 , 180, 3), dtype=np.uint8) # H(色相)は0から179までの連続する整数にする for i in range(180): h_map[:, i, 0] = i # S(彩度)はすべて255にする h_map[:, :, 1] = 255 # V(明度)はすべて255にする h_map[:, :, 2] = 255 h_map = cv2.cvtColor(h_map, cv2.COLOR_HSV2BGR) fig = plt.figure(figsize=(3,1), dpi=200) # グラフの領域:横600px, 縦200px plt.imshow(cv2.cvtColor(h_map, cv2.COLOR_BGR2RGB))
出力結果:

特定の色合いの部分だけを抽出する
グラフを見るとわかるように、HSV形式においては、似た色合いの色同士はHが近い数値になります。たとえば青系統の色のHの値は、90~130ぐらいの範囲です。そこでこの性質を利用して、画像から「赤い部分」「青い部分」など、特定の色合いの部分を抽出できます。
実際にやってみましょう。青い風船が写っている画像(home2.jpg。前のチャプターで im2
として使用したもの)から、青っぽい部分を抽出することで、風船の写っている部分だけを抜き出してみましょう。
マスク画像を作る
まずは該当箇所の2値化画像を作成します。ここでは、いったん画像をHSV形式に変換したのち、ここでは、[90, 100, 100]から[130, 255, 255]の範囲にあるかどうかで2値化します(この値は、実際の画像をフォトレタッチソフトで読み込んで、それらしき範囲を調べたものです。この範囲を調整すれば、よりよい精度で抽出できます)。
値の範囲で2値化するには、cv2.inRangeを使います。inRangeは指定した範囲内にあれば255、そうでなければ0を設定したグレースケールの(1次元の)ndarrayを返します。そこで、この得られたndarrayをBGRすべてに設定することで、カラー化したマスク画像を作ります。
下記のプログラムを実行すると、青い風船のあたりだけが抽出されたマスク画像を作れます。
# home2.png画像の読み込み im2 = cv2.imread('home2.png') # HSV形式に変換 im2_hsv = cv2.cvtColor(im2, cv2.COLOR_BGR2HSV) im2_width, im2_height, im2_col = im2_hsv.shape # H,S,Vそれぞれの下限値と上限値 lower_blue = np.array([90, 100, 100]) upper_blue = np.array([130, 255, 255]) # 各ピクセルが上限値と下限値の間に入るかどうかで2値化する im2_mask = cv2.inRange(im2_hsv, lower_blue, upper_blue) # マスキング用のデータ(すべて0で初期化) im2_mask_img = np.zeros((im2_width, im2_height, 3), dtype=np.uint8) # BGRすべてで2値化 for i in range(3): im2_mask_img[:, :, i] = im2_mask # 2値化した画像の表示 plt.imshow(cv2.cvtColor(im2_mask_img, cv2.COLOR_BGR2RGB))
出力結果:

マスキングして表示する
マスク画像ができたら、cv2.bitwise_andを使ってマスキングします。風船らしい部分を抜き出すことができました。
# im2の画像と2値化した画像でマスキング im2_masked = cv2.bitwise_and(im2, im2_mask_img) # マスキングした画像の表示 plt.imshow(cv2.cvtColor(im2_masked, cv2.COLOR_BGR2RGB))

Lesson 8Chapter 3.3
輪郭の抽出
OpenCVには、画像処理するためのさまざまな機能があります。たとえばcv2.findContours()を使うと、輪郭を抽出できます。
前段階の2値化
輪郭を取得する場合、カラー画像よりも2値画像に対して処理したほうが精度は高いので、まずは、2値化します。ここでは、上で求めた、青い風船だけを抜き出した画像を使います。
まずcv2.cvtColorを使ってグレースケールに変換してから2値化します。2値化処理には、cv2.threadsholdを使いました。この関数は、さまざまな2値化に利用できる関数で、cv2.threadhold(画像,
しきい値, しきい値を超えたときに設定する値, 方法)のように使います。
下記の例では、方法としてcv2.THRESH_BINARYを指定。しきい値として0、しきい値として超えたときに設定する値として255をそれぞれ指定することで、「0より大きければ(つまり、少しでも色が付いていれば)255にする」という2値化をしています。
# 画像から輪郭になるものを抽出 im2_masked_gray = cv2.cvtColor(im2_masked, cv2.COLOR_BGR2GRAY) ret, im2_masked_gray = cv2.threshold(im2_masked_gray, 0, 255, cv2.THRESH_BINARY) plt.imshow(im2_masked_gray, cmap="gray")
出力結果

(補足)
cv2.THRESH_BINARYの代わりにcv2.THRESH_BINARY_INVを使うと、白黒を反転できます。それ以外にも、緩やかにあたいを変化させるなどいくつかの方法を選択できます。詳しくは、OpenCVのドキュメントを参照してください。
輪郭の抽出と描画
この画像に対してcv2findControusを使うと、輪郭、つまり、白い部分を囲むような領域がわかります。
contours, hierarchy = cv2.findContours(im2_masked_gray,cv2.RETR_LIST,cv2.CHAIN_APPROX_SIMPLE)
上記のように実行した場合、結果は、頂点の数(contours)と囲む領域を示す多角形の頂点のリスト(hierarcy)として得られます。
この結果を使って次のようにすれば、得られた輪郭を描画できます。多角形の描画には、cv2.polylinesを使いました。結果には、いくつかゴミが含まれることもあるので、ここでは面積が1000より小さい場合はゴミとして扱い、描画しないようにしました。面積を求めるには、cv2.contourAreaを使っています。
# 元画像のコピーを作成 im2_draw_line = np.copy(im2) # ゴミのデータも混じっているのでループにして選別 for i in range(len(contours)): # 面積が大きくないものはゴミのデータとして無視する contour = contours[i] c_area = cv2.contourArea(contour) if c_area < 1000: continue # 風船を長方形で囲む cv2.polylines(im2_draw_line, contours[i], True, (0, 0, 255), 2) # 輪郭線の入った画像を表示 plt.imshow(cv2.cvtColor(im2_draw_line, cv2.COLOR_BGR2RGB))
出力結果

マーキング
多角形のX座標の最小値、最大値、Y座標の最小値、最大値を囲む四角形を描画すれば、物体全体を囲むような四角形を描画できます。多角形の頂点リストから、それを囲む四角形の情報を得るには、cv2.boundingRectを使います。
# 元画像のコピーを作成 im2_draw_rect = np.copy(im2) # 画像から輪郭になるものを抽出 im2_masked_gray = cv2.cvtColor(im2_masked, cv2.COLOR_BGR2GRAY) ret, im2_masked_gray = cv2.threshold(im2_masked_gray, 0, 255, cv2.THRESH_BINARY) contours, hierarchy = cv2.findContours(im2_masked_gray,cv2.RETR_LIST,cv2.CHAIN_APPROX_SIMPLE) # ゴミのデータも混じっているのでループにして選別 for i in range(len(contours)): # 面積が大きくないものはゴミのデータとして無視する contour = contours[i] c_area = cv2.contourArea(contour) if c_area < 1000: continue # 風船の左上の座標と幅・高さの情報を取得 x, y, w, h = cv2.boundingRect(contour) # 風船を長方形で囲む cv2.rectangle(im2_draw_rect,(x, y), (x + w, y + h), (0, 0, 255), 2) # 囲った線の入った画像を表示 plt.imshow(cv2.cvtColor(im2_draw_rect, cv2.COLOR_BGR2RGB))
出力結果

Lesson 8Chapter 3.4
畳み込み
畳み込みとは、元のデータに対して、ある値(関数)を、少しずつズラしてかけて足し合わせた値を求める方法です。
あるデータの周辺の値を取り込みながら計算する方法で、たとえば音声データに対して畳み込みすると、音の平滑化や残響効果を作れます。また画像に対して畳み込みをすれば、平滑化することでノイズを減らしたり、ブレの効果を出したりできます。
OpenCVでは、cv2.filter2d()を使うことで、畳み込み演算できます。ここでは畳み込み演算を使うことで画像を平滑化し、ノイズを除去してみます。
対象の画像の準備
サンプルとして利用するのは、前のチャプター内の「単純な引き算」で行った、「風船がある画像(home2.png)」と「風船がない画像(home1.png)」の差の画像を利用します。次のようにim2_im1_noiseという変数で用意します。実行結果を見るように、この画像には、ポツポツと小さなノイズが含まれています。
# home1.png画像の読み込み im1 = cv2.imread('home1.png') # home2.png画像の読み込み im2 = cv2.imread('home2.png') # home2からhome1を引き算した画像 im2_im1_noise = im2 - im1 # ノイズが入った画像を表示 plt.imshow(cv2.cvtColor(im2_im1_noise, cv2.COLOR_BGR2RGB))
出力結果:

畳み込みによる平滑化
ここでは次のように、すべての要素に「1/9」の値を格納した3×3の行列を作って、それを画像に対して畳み込み演算します。畳み込み演算に使う行列のことを、カーネル(kernel)と呼びます。

この行列を、np.one(3, 3)で全要素の値が1の3×3の行列を用意したあと、それを9で割って作れます。
kernel = np.ones((3, 3)) / 9.0
kernel
出力結果
array([[0.11111111, 0.11111111, 0.11111111],
[0.11111111, 0.11111111, 0.11111111],
[0.11111111, 0.11111111, 0.11111111]])
この行列を画像に対して畳み込み計算すると、周囲のピクセルの値を1/9ずつ取得して新たな値を計算します。つまり周囲のピクセルの平滑化が実行されます。その結果、小さなノイズが除去される効果を得られます。このような行列で平滑化する操作は、ブラーフィルタ(blurフィルタ)とも呼ばれます。

実際のプログラムは、下記の通りです。cv2.filter2Dに渡している-1は、ビット深度を指定する値で、簡単に言えば、色数のことです。負の値を指定すると、元の画像と同じになるので、ここでは-1を渡しています。
実行結果を見るとわかるように、ノイズが減っていることがわかります。
# filter2D()を使って平滑化 im2_im1_filtered = cv2.filter2D(im2_im1_noise, -1, kernel) # 平滑化した画像の表示 plt.imshow(cv2.cvtColor(im2_im1_filtered, cv2.COLOR_BGR2RGB))
出力結果:

Lesson 8Chapter 3.5
画像のノイズ除去
画像をノイズ除去する場合、OpenCVの機能を使うこともできます。
(1)ブラーフィルタ
ひとつめの方法は、cv2.blurを使う方法です。これは先ほど実行したfilter2Dで使った行列と同じものを用意してフィルタします。この結果は、先ほどのものと同じで、畳み込みの行列が登場しない分、簡単です。
# blur()を使って平滑化 im2_im1_blured = cv2.blur(im2_im1_noise, (3, 3)) # 平滑化した画像の表示 plt.imshow(cv2.cvtColor(im2_im1_blured, cv2.COLOR_BGR2RGB))
出力結果:

(2)中央値フィルタ(メシアンブラーフィルタ)
もうひとつの方法は、cv2.medianBlurを使う方法です。これは周りのピクセルの平均値を使って中央のピクセルの値を計算をする方法です。結果を見るとわかるように、先の例よりも、細かいノイズが消えていることがわかります。
# medianBlur()を使って平滑化 im2_im1_median_blured = cv2.medianBlur(im2_im1_noise, 3) # 平滑化した画像の表示 plt.imshow(cv2.cvtColor(im2_im1_median_blured, cv2.COLOR_BGR2RGB))
出力結果

Lesson 8Chapter 3.6
ライン(エッジ)の検出
輪郭の抽出は、すでに、2値化してcv2findControusする求め方を学びました。OpenCVでは、もっと簡単で高精度な方法があります。
エッジ検出の基本的な方法
画像のエッジ(輪郭)抽出で多く用いられているのがCanny法です。OpenCVではcv2.Canny()として実装されています。cv2.Canny()の使い方は以下のとおりです。結果(出力画像)はグレースケールの画像として得られます。
出力画像 = cv2.Canny(入力画像, しきい値1, しきい値2)
しきい値の意味について説明します。画像はOpenCVの公式ページより引用しています。

Canny法では画像の輝度の変化が大きい部分をエッジとして抽出します。輝度の変化は微分により求めています。値が大きいほど輝度の変化が大きいということになります。その値を「しきい値1、しきい値2」で判断してエッジかどうかを決めます。
- しきい値1は図のminValに該当します。minVal未満はエッジではないと判断します
- しきい値2は図のmaxValに該当します。maxValより大きいものはエッジと判断します
- minValとmaxValの間は、隣接する画素をもとに判断します
- 図のBは隣接する画素にエッジがないためエッジとは判断されません
- 図のCは隣接する画素にAが存在するためエッジと判断されます
このようなminValとmaxValの間の判断方法をヒステリシスしきい値による処理と呼びます。ヒステリシスとはある物質の状態が現在だけでなく過去に加えられた力にも影響されている状況をいい、製造業などでも広く使われている考え方です。Canny法では「エッジは長い線である」という前提のもと、隣接する画素をもとにヒステリシスしきい値によってエッジかどうかの判断を行います。
それでは改めてしきい値1としきい値2の値の調整方法について見ていきましょう。
- しきい値1としきい値2:共に値が小さいほどエッジが検出されやすく、大きいほどエッジが検出されにくくなります
- しきい値2:全体のエッジの検出度合いを決めます
- しきい値1:見つかったエッジと隣接する部分で、それをエッジと判断するかどうかの度合いです。見つかったエッジがブツブツと切れてしまうようなときは値を小さくします。逆に、ムダなエッジが伸びてしまっているようなときは、この値を小さくします。
これらの2つの値は、試行錯誤して、適切なものを選ぶようにするとよいでしょう。下記に、cv2.Cannyを使ってエッジ検出する例を示します。thradshold1とthreadshold2の値を、いくつか変更して試してみて、結果がどうなるか試してみてください。
# Canny()を使ってim2から風船と椅子のエッジを検出 im2_edged = cv2.Canny(im2, 100, 330) # 検出したエッジの画像を表示 plt.imshow(im2_edged, cmap="gray")
出力結果:

(補足)エッジの膨張と収縮
cv.dilateとcv.erodeを使うと、それぞれ輪郭を膨張したり、収縮したりできます。下記に、求めたエッジを膨張したり、収縮したりする例を示します。こうした処理は、見つけた領域をひとまわり大きくしたり、小さくしたりするときに使います。
エッジ処理以外にも、文字を太くしたり、細くしたりする効果を出したいときなどにも使えます。
(1)膨張する例
# エッジを膨張させる im2_edge_dilated = cv2.dilate(im2_edged, kernel) # 膨張させたエッジの画像を表示 plt.imshow(im2_edge_dilated, cmap="gray")
出力結果

- 収縮する例
# 膨張させたものを逆に収縮させる im2_edge_dilate_eroded = cv2.erode(im2_edge_dilated, kernel) # 膨張させて収縮させたエッジの画像を表示 plt.imshow(im2_edge_dilate_eroded, cmap="gray")
出力結果:

Lesson 8Chapter 3.7
ヒストグラム(明度の分布)の操作
ヒストグラムは、ある値が、どの程度含まれているのかをグラフにしたものです。グレースケール画像に対してヒストグラムを確認すれば、明暗の分布がわかります。カラー画像に対してヒストグラムを確認すれば色合いの分布を確認できます。
対象画像の読み込み
ヒストグラム確認用に以下の木の写真画像を利用します。この写真を右クリック→「名前をつけて保存」(ファイル名は tree.jpg のままで保存)して、JupyterLabのノートブックと同じディレクトリに置いてください。

画像を保存したらcv2.imreadを使って読み込んでみましょう。
# tree.jpg画像の読み込み tree = cv2.imread('tree.jpg') # 画像の表示 plt.imshow(cv2.cvtColor(tree, cv2.COLOR_BGR2RGB))
出力結果:

画像の大きさも取得しておきます。
tree_height, tree_width, tree_colornum = tree.shape print(tree_height) print(tree_width) print(tree_colornum)
出力結果
480
640
3
ヒストグラムの作成
ヒストグラムを作るには、cv2.calcHist()関数を使います。書式は次の通りです。
cv2.calcHist(images, channels, mask, histSize, ranges)
images
入力画像のリストです。ひとつだけの画像を指定するときは、[画像]のようにリストで渡します。channels
ヒストグラムを計算する対象のインデックスです。BGR形式の場合は[0]がB、[1]はG、[2]がRに相当します。グレースケール画像のときは[0]を指定します。mask
特定の部分だけのヒストグラムを計算したいときは、その範囲を指定するマスク画像を指定します。Noneを指定すると、すべての範囲を対象とします。histSize
分割数(ビンのサイズ)です。ひとつずつ求めるのなら[256]を指定します。仮に[16]とすれば、0~15の範囲、16~31の範囲、…というように16分割した結果が得られます。ranges
求める範囲を指定します。0~255の全範囲を対象とするなら[0, 256]を指定します(最後の値は、その値を含まないので、1大きくする点に注意してください)。
ヒストグラムの確認
それでは実際にヒストグラムを作成し、内容を確認してみましょう。ここではtree.jpgを読み込んだ変数treeの青要素(B)のヒストグラムを確認してみます。まずは変数treeの青要素(B)を可視化してみます。
# 青のみの単色化 tree_b = np.zeros((tree_height, tree_width, 3), dtype=np.uint8) tree_b[:, :, 0] = tree[:, :, 0] plt.imshow(cv2.cvtColor(tree_b, cv2.COLOR_BGR2RGB))
出力結果:

可視化した結果から、木や建物の明るさが低い部分と、空の明るさが明るい部分とに大きく別れていることが確認できます。それではcalcHist()関数を使ってヒストグラムを計算、表示してみましょう。
# cv2のcalcHist()を使って青の成分のヒストグラムを計算・表示 tree_hist = cv2.calcHist([tree],[0],None,[256],[0,256]) plt.plot(tree_hist)
出力結果:

ヒストグラムは、横軸が値、縦軸が含まれているデータ数です。この結果から、青い要素は、50前後と200前後にピークがあることを見て取れます。先ほどのイメージと対応付けた場合、以下のようになります。

次にRGBの3色でヒストグラムを作成してみましょう。まずはRGBそれぞれに単色化した画像を表示します。
# 青のみの単色化 tree_b = np.zeros((tree_height, tree_width, 3), dtype=np.uint8) tree_b[:, :, 0] = tree[:, :, 0] # 緑のみの単色化 tree_g = np.zeros((tree_height, tree_width, 3), dtype=np.uint8) tree_g[:, :, 1] = tree[:, :, 1] # 赤のみの単色化 tree_r = np.zeros((tree_height, tree_width, 3), dtype=np.uint8) tree_r[:, :, 2] = tree[:, :, 2] # 単色化した画像を横に並べて表示 tree_monos = cv2.hconcat([tree_b, tree_g, tree_r]) plt.imshow(cv2.cvtColor(tree_monos, cv2.COLOR_BGR2RGB))
出力結果:

ヒストグラムを重ねて表示してみましょう。それぞれの色の成分の分布に違いがあることを見て取れます。
# RGB(赤緑青)のヒストグラムを重ねて表示 # 赤の成分 tree_hist = cv2.calcHist([tree],[2],None,[256],[1,255]) plt.plot(tree_hist, color="red") # 緑の成分 tree_hist = cv2.calcHist([tree],[1],None,[256],[1,255]) plt.plot(tree_hist, color="green") # 青の成分 tree_hist = cv2.calcHist([tree],[0],None,[256],[1,255]) plt.plot(tree_hist, color="blue")
出力結果:

ヒストグラムの平坦化による明るさの調整
グレースケールの画像に対してヒストグラム平坦化すると、明るさを調整して画像を見やすくできます。フォトレタッチソフトにおける「明るさの自動調整」と似た結果が得られます。
実際にやってみます。まずはグレースケール画像を用意します。
# 木の画像をグレースケール化する tree_gray = cv2.cvtColor(tree, cv2.COLOR_BGR2GRAY) plt.imshow(tree_gray, cmap='gray')
出力結果:

このグレースケール画像に対するヒストグラムは以下のようになります。x軸方向の輝度変化(明るさの変化)の範囲が20~160に集中していることが分かります。人間の目は輝度変化に気づきやすいため、この輝度変化の幅を広げることで、暗いものはより暗く、明るいものはより明るくなり画像を見やすくできます。
# グレースケール画像のヒストグラムを表示 tree_gray_hist = cv2.calcHist([tree_gray],[0],None,[256],[0,256]) plt.plot(tree_gray_hist)
出力結果:

平坦化には、cv2.equalizeHistを使う方法と、cv2.createCLAHEを使う方法の2通りがあります。
(1)cv2.equalizeHistを使う方法
画像全体に対してヒストグラム平坦化を実行する方法です。元の画像に比べて雲の部分がより明るくなり、見やすくなっていることが分かります。また、もとの画像と比較して少しざらついた印象もあります。
# equalizeHist()を使ってヒストグラムを平坦化して表示 tree_equalized = cv2.equalizeHist(tree_gray) plt.imshow(tree_equalized, cmap="gray")
出力結果:

平坦化した画像のヒストグラムを表示してみましょう。平坦化する前のヒストグラムを黒、平坦化後のヒストグラムを赤で表示しています。x軸方向の輝度変化の幅が0~255全体に広がっていることが分かります。その代わり、y軸方向に値のブレがあります。
# equalizeHist後のヒストグラム tree_gray_equalized_hist = cv2.calcHist([tree_equalized],[0],None,[256],[0,256]) plt.plot(tree_gray_equalized_hist, color="red") # グレースケール画像のヒストグラム tree_gray_hist = cv2.calcHist([tree_gray],[0],None,[256],[0,256]) plt.plot(tree_gray_hist)
出力結果:

少し拡大してみましょう。輝度0~63の範囲を拡大してみます。y軸方向の値のブレは、その輝度に該当するピクセルの数が前後の輝度と比べて大きく変化していることを表しています。これがざらついた印象の正体です。
# equalizeHist後のヒストグラム tree_gray_equalized_hist = cv2.calcHist([tree_equalized],[0],None,[64],[0,64]) plt.plot(tree_gray_equalized_hist, color="red") # グレースケール画像のヒストグラム tree_gray_hist = cv2.calcHist([tree_gray],[0],None,[64],[0,64]) plt.plot(tree_gray_hist, color="black")
出力結果:

(2)cv.createCLAHEを使う方法
もうひとつの方法が「CLAHE(Contrast Limited Adaptive Histogram
Equalization)」という手法です。この手法では、画像全体をヒストグラム平坦化するのではなく、小さなブロック単位で分けて、そのブロックのなかでヒストグラム平坦化を行います。暗いところは暗めに、明るいところは明るめにというように局所で平坦化するため、cv2.equalizeHistよりも結果が良好になることが多いです。先ほどより、ざらついた感じが少なく、なめらかな結果を得られたことが分かります。
# CLAHE(適用的ヒストグラム平坦化)を使ってヒストグラムを平坦化して表示 clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(3, 3)) tree_clahe = clahe.apply(tree_gray) plt.imshow(tree_clahe, cmap="gray")
出力結果:

ヒストグラムにすると一目瞭然です。y軸方向の値のブレがequalizeHistと比較して小さくなっています。よりなめらかに平坦化が行われています。
# CLAHE後のヒストグラム tree_clahe_hist = cv2.calcHist([tree_clahe],[0],None,[256],[0,256]) plt.plot(tree_clahe_hist, color="red") # グレースケール画像のヒストグラム tree_gray_hist = cv2.calcHist([tree_gray],[0],None,[256],[0,256]) plt.plot(tree_gray_hist, color="black")

(補足)ガンマ補正
明るさを変える方法としては、ヒストグラムの平坦化以外にガンマ補正をかける方法もあります。
ガンマ補正とは、各ピクセルの値に特定の式をあてはめて計算する方法で、輝度や色の値と実際の表示の濃さとの関係を、直線的ではなく曲線的に変換します。具体的なガンマ補正の方法については、次のチャプターで説明します。
Lesson 8Chapter 3.8
(参考)2次元ヒストグラム
cv2.calcHistのchannelsに2つの値を渡すと、2次元ヒストグラムを作成できます。たとえばHSV形式の画像tree_hsvを用意しchannelに[0,
1]を渡すと、「H(色相)」と「S(彩度)」の関係を2次元ヒストグラムにできます。
下記に例を示します。下記の例では、結果をわかりやすくするため、ビンを[22,
32]としました。つまりH(色相)は22分割(≒180÷8)、S(彩度)は32分割(=256÷8)したものとしています。
# HSVに変換 tree_hsv = cv2.cvtColor(tree, cv2.COLOR_BGR2HSV) # 2次元ヒストグラムの表示(im2_hsvを使う) tree_hist2d = cv2.calcHist([tree_hsv], [0, 1], None, [22, 32], [0, 180, 0, 256]) # ヒストグラムの表示 plt.imshow(tree_hist2d, cmap="gray")
出力結果:

色相と比較してみましょう。125付近、すなわち青い色の部分が多くでています。これはもとの画像で青色の部分が多いことを表しています。
彩度のヒストグラムと比較してみましょう。50から200にかけての成分の多い部分が、2次元ヒストグラムにでていることが分かります。このことから、もとの画像は彩度が50~200の青色の成分が多いということがひと目で判断できます。
# 彩度のヒストグラムを表示 tree_sa_hist = cv2.calcHist([tree_hsv[:,:,1]],[0],None,[256],[0,255]) plt.plot(tree_sa_hist)
出力結果:

Lesson
8Chapter 4
OpenCVを用いた地理空間情報解析
Lesson 8Chapter 4.1
学習の目標
このチャプターでは、衛星データをダウンロードして画像処理する基本的な方法を説明します。
Lesson 8Chapter 4.2
衛星データの地理空間情報解析
インターネットでは衛星データが公開されています。衛星データは、波長ごとに分割された画像であり、そのままではフルカラー画像として見ることができません。ここでは、欲しい衛星データをダウンロードし、OpenCVで処理して解析して、必要な見やすい画像に加工する方法を習得します。
Sentinel衛星シリーズ
さまざまな衛星がありますが、ここではESAがCopernicus Programmeの一環として展開しているSentinel衛星シリーズのデータを用います。
「Sentinel-1」「Sentinel-2」「Sentinel-3」「Sentinel-5P」の4つの衛星があり、ここでは、陸域を対象としている「Sentinel-2」のデータを使って、衛星から送られてくる波長データを組み合わせた画像を表示してみます。
| Sentinel-1 | Sentinel-2 | Sentinel-3 | Sentinel-5P | |
|---|---|---|---|---|
| 観測方法(観測域) | SAR(C) | 光学(VIS/NIR) | 放射計(VIS/NIR/SWIR) | 分光観測(UV/VIS/NIR/SWIR) |
| 観測対象 | 陸域・海域 | 陸域 | 海域 | 空域 |
| 主な用途 | 森林伐採監視、船舶検出、地表面変化 | 土地被覆分類、植生変化、都市開発 | 海色、海面水温、水質、植生分布 | オゾン、一酸化炭素、エアロゾル |
Sentinel衛星シリーズのユーザーアカウントを作成する
Sentinel衛星のデータを利用するには、ユーザー登録が必要です。次のようにしてアカウントを作成してください。
- Sentinel Hubにアクセスする
下記のURLにアクセスします。
https://scihub.copernicus.eu/dhus/ - サインアップする
地図が表示されるので、左上の人のアイコンをクリックし、[Sign up]のリンクをクリックします。

- 必要事項を入力する
氏名、メールアドレス、ユーザー名、パスワードなどの必要事項を入力して登録します。「Username」がアクセスするときのユーザー名(アカウント名)、「Password」がパスワードです。ユーザー名とパスワードは、プログラムからアクセスするときの認証に使います。

- メール検証する
メールが届くので、記載されているURLにアクセスします。
Lesson 8Chapter 4.3
ライブラリの準備
この先の内容を実習するためには、いくつかのライブラリのインストールが必要です。
- Sentinelsat
Sentinel衛星のAPIにアクセスし、検索したり、ダウンロードしたりするためのライブラリです。 - Rasterio
GISデータを操作するライブラリです。 - Geopandas
地理情報を扱うライブラリです。
Mac、Windowsのそれぞれで、次のようにしてインストールしてください。
Macの場合
以下の命令を1つずつ、ノートブック上のセルにコピペして実行すればOKです。
!pip --no-cache-dir install sentinelsat==0.14
!pip --no-cache-dir install rasterio==1.1.6
!pip --no-cache-dir install geopandas==0.8.1
Windowsの場合
Sentinelsatのみ、以下の命令でインストールできます。ノートブックのセルにコピペして実行します。
!pip --no-cache-dir install sentinelsat==0.14
RasterioとGeoPandasは、単純なpipコマンドでWindowsにインストールした場合、正常に動作しない可能性があります。そこで、https://www.lfd.uci.edu/~gohlke/pythonlibs/ で配布されているパッケージからインストールします。こちらは、米カリフォルニア大学の研究員の方による、Windowsで問題なく動作するようにカスタマイズしたPythonパッケージを配布しているサイトです。
なお、上記2つに加え、それらが内部で利用している以下のライブラリも併せて、上記のサイトからダウンロードする必要があります。(こちらのライブラリは、今回の学習内容では直接操作しません)
- GDAL
- pyproj
- Fiona
- Shapely
- Pylibjpeg(OpenJPEG版)
パッケージのダウンロード
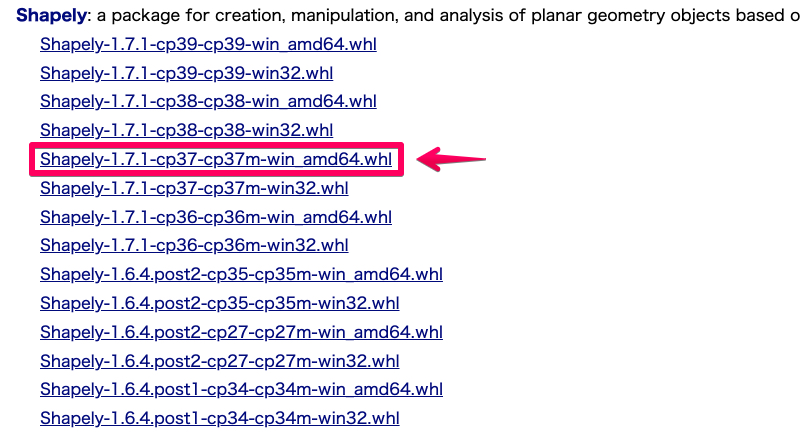
各種ライブラリを上記サイトから取得します。それぞれ、いくつかのダウンロードリンクがありますが、‑cp37‑cp37m‑win_amd64.whl
という文字列のついているものが、WindowsかつPython3.7に対応したライブラリです。
- GDAL
GDAL-3.◯.△-cp37-cp37m-win_amd64.whlという名前のファイルをダウンロードします。(下記の場合はGDAL-3.1.4-cp37-cp37m-win_amd64.whl)

- Rasterio
rasterio‑1.◯.△‑cp37‑cp37m‑win_amd64.whlという名前のファイルをダウンロードします。(下記の場合はrasterio‑1.1.8‑cp37‑cp37m‑win_amd64.whl)

- Pyproj
pyproj‑2.6.◯◯‑cp37‑cp37m‑win_amd64.whlという名前のファイルをダウンロードします。(下記の場合はpyproj‑2.6.1.post1‑cp37‑cp37m‑win_amd64.whl)

- Fiona
Fiona‑1.8.◯‑cp37‑cp37m‑win_amd64.whlという名前のファイルをダウンロードします。(下記の場合はFiona‑1.8.18‑cp37‑cp37m‑win_amd64.whl)

- Shapely
Shapely‑1.◯.△‑cp37‑cp37m‑win_amd64.whlという名前のファイルをダウンロードします。(下記の場合はShapely‑1.7.1‑cp37‑cp37m‑win_amd64.whl)
- Pylibjpeg(OpenJPEG版)
pylibjpeg_openjpeg‑1.◯.△‑cp37‑cp37m‑win_amd64.whlという名前のファイルをダウンロードします。(下記の場合はpylibjpeg_openjpeg‑1.0.1‑cp37‑cp37m‑win_amd64.whl)

- GeoPandas
Misc の欄には多くのライブラリが紹介されています。その中でgeopandas‑0.◯.△‑py3‑none‑any.whlという名前のファイルをダウンロードします。(下記の場合はgeopandas‑0.8.1‑py3‑none‑any.whl)

ダウンロードしたファイルは、ノートブックと同じフォルダに入れてください。その状態で、以下の命令を1つずつ、ノートブックのセルにコピペして実行します。
!pip --no-cache-dir install GDAL-3.1.4-cp37-cp37m-win_amd64.whl
!pip --no-cache-dir install rasterio-1.1.8-cp37-cp37m-win_amd64.whl
!pip --no-cache-dir install pyproj-2.6.1.post1-cp37-cp37m-win_amd64.whl
!pip --no-cache-dir install Fiona-1.8.18-cp37-cp37m-win_amd64.whl
!pip --no-cache-dir install Shapely-1.7.1-cp37-cp37m-win_amd64.whl
!pip --no-cache-dir install pylibjpeg_openjpeg-1.0.1-cp37-cp37m-win_amd64.whl
!pip --no-cache-dir install geopandas-0.8.1-py3-none-any.whl
インストールは以上で完了です。
Lesson 8Chapter 4.4
Sentinel-2データの基本操作
準備ができたので、Sentinelsatライブラリを使って、早速、Sentinel-2のデータを取得していきましょう。ここでは基本的なAPIの使い方を抜粋します。API仕様については、下記のドキュメントを参考にしてください。
https://sentinelsat.readthedocs.io/en/stable/api.html
ライブラリのインポート
まずは必要なライブラリをインポートします。
# 必要なライブラリのインポート import matplotlib.pyplot as plt import numpy as np import os os.environ["OPENCV_IO_ENABLE_JASPER"] = "True" from sentinelsat import SentinelAPI, read_geojson, geojson_to_wkt import shutil import cv2 %matplotlib inline
ユーザー認証
最初にユーザー認証して、APIを利用できるようにします。Sentinel Hubに登録した「ユーザー名」と「パスワード」を使います。
# 認証 user = 'ユーザー名' passwd = 'パスワード' api = SentinelAPI(user, passwd, 'https://scihub.copernicus.eu/dhus')
読み込み範囲の指定
Sentinel APIで画像データを読み込むときは、どの範囲のデータなのかという領域を引数として渡す必要があります。そこで事前に、その領域を準備します。
いくつかの方法がありますが、ここでは下記のサイトにアクセスし、地図上をマウスで範囲選択して、その範囲をJSONデータとして作ることにします。
- 地図上の領域を選択する
サイトに訪れると、地図が表示されます。四角形の範囲選択ツールを使って地図上で範囲を選択すると、その領域を示すJSONデータが表示されます。ここでは東京周辺を選択することにします。

- JSON形式データとして保存する
左上の[Save]メニューから[GeoJSON]を選択します。するとJSONデータとしてダウンロードできます。 - ノートブックと同じ場所に移動する
2でダウンロードしたファイルを、Jupyter Notebookのノートブックと同じ場所に配置してください。
このように https://geojson.io/ を使えば自由な範囲で指定できるのですが、指定した範囲によって結果が違って、学習内容としてわかりにくくなってしまいます。
そこでここでは皆さんの結果が同じになるよう、あらかじめこちらで用意したtokyo_bay.geojsonというファイルを利用することにします。下記のファイルをダウンロードし、Jupyter
Notebookのノートブックと同じ場所に配置してください。
Sentinel APIでは、領域をWKT(Well-known text)形式で扱います。そこでSentinel
APIのread_geojsonを使って、このJSONファイルを読み込み、geojson_to_wktを使ってWKT形式に変換します。
# 東京湾周辺が指定されたGeoJSONのデータを読み込む footprint_geojson = geojson_to_wkt(read_geojson('tokyo_bay.geojson'))
Sentinel-2データの取得
準備ができたので、Sentinel-2のデータを取得しましょう。queryを使うと、条件に合致する画像を取得できます。
ここでは次の条件の画像をダウンロードしてみます。
- 範囲
先ほどマウスで範囲指定したmap.getjsonの範囲 - 日付
2019年12月1日~2020年1月10日まで - 条件
被雲率(cloudcoverpercentage)が0%~100%の範囲
すぐあとに説明しますが、衛星データの鮮明度は、そのときの雲の様子が左右します。そのため衛星データを使うときは、ある程度の期間の衛星データを何枚かダウンロードし、そのうちのもっとも雲がかかっていない(被雲率が小さい)ものを採用するというやり方が、よくされます。
さて、こうした条件のデータをダウンロードするには、次のようにします。
# Sentinel-2のデータを取得 products = api.query(footprint_geojson, date = ('20191201', '20200110'), #取得希望期間の入力 platformname = 'Sentinel-2', processinglevel = 'Level-2A', cloudcoverpercentage = (0,100)) #被雲率(0%〜100%)
引数の意味は、次の通りです。
footprint_geojson
取得する範囲です。すでに生成したmap.geojsonから読み取った範囲を指定しています。date
取得する期間です。ここでは2019年12月1日から2020年1月10日までのデータを取得しようとしています。platformname
該当の衛星の名前です。ここではSentinel-2を指定しました。processinglevel
プロダクトの種類です。Sentinel-2の場合、「Level-1C」と「Level-2A」があります(https://sentinel.esa.int/web/sentinel/user-guides/sentinel-2-msi/product-types)。
前者は大気上部(TOA)の反射率、後者は大気圏下 反射率(BOA)に基づくものです。ここではLevel-2Aを使います。
https://sentinel.esa.int/web/sentinel/user-guides/sentinel-2-msi/product-typescloudoverpercentage
指定している条件のうちのひとつ、被雲率です。0~100までの範囲を指定しています。
(補足)
利用できる引数についてはhttps://scihub.copernicus.eu/twiki/do/view/SciHubUserGuide/FullTextSearchを参考にしてください。
画像のダウンロードと展開
実行したら戻り値を確認してみましょう。まずはデータ個数を確認してみます。この期間に8枚の画像があるようです。
len(products)
出力結果:
8
このなかから、もっとも雲がかかっていない画像を使いましょう。それには被雲率(cloudcoverpercentage)の昇順で並べ替えます。
# 被雲率の昇順で並び替え products_gdf = api.to_geodataframe(products) products_gdf_sorted = products_gdf.sort_values(['cloudcoverpercentage'], ascending=[True]) products_gdf_sorted
出力結果:

データのなかにlinkという項目があります。これが画像をダウンロードするためのURLです。このURLをブラウザで開けば画像をダウンロードできます。先頭のURLは、次のようにして確認できます。
# 観測画像のダウンロードURLを表示(表示内容をそのままブラウザのURL欄にコピペで入力) print(products_gdf_sorted.iloc[0]['link'])
出力結果:
https://scihub.copernicus.eu/dhus/odata/v1/Products('a73fcc80-4850-4ab4-a199-301441307a0e')/$value
また、api.download()を用いてデータをダウンロードすることもできます。その場合は、作業ディレクトリ内にデータは保存されます。
# 衛星データのダウンロード index = products_gdf_sorted.index[0] api.download(index) # ダウンロードしたファイルの解凍 title = products_gdf_sorted.title[0] shutil.unpack_archive(title+'.zip')
ダウンロードしたファイルを解凍すると、.SAFEというファイルが生成されます。SAFE(Standard Archive Format for Europe)は複数のフォルダをもったファイル程度の理解で大丈夫です。今回は、[GRANULE]→[L2A_T54SUE_AXXXXXXXXXXXXX](XXXXXXはそれぞれ異なる名前)→[IMG_DATA]→[R10m]フォルダと、そのなかに含まれている画像ファイルのみを使います。
# 衛星データのR10mフォルダのファイル名をリストで返す関数 def strpjp2(productTitle): path = str(productTitle) + '.SAFE/GRANULE' files = os.listdir(path) pathA = str(productTitle) + '.SAFE/GRANULE/' + str(files[0]) files2 = os.listdir(pathA) pathB = str(productTitle) + '.SAFE/GRANULE/' + str(files[0]) +'/' + str(files2[1]) +'/R10m' files3 = os.listdir(pathB) filepath = [] for file in files3: filepath.append(pathB+'/'+file) return(sorted(filepath))
上記の関数を使って衛星データからコピーするファイル名を取得し、フォルダの作成、ファイルのコピーを行います。
# 衛星データのファイル名をリストで取得 path = strpjp2(title) # 作成するフォルダ名 foldername = 'R10m' # フォルダが存在していたら削除 if os.path.exists(foldername): shutil.rmtree(foldername) # フォルダを作成 os.makedirs(foldername,exist_ok=True) # 衛星データのファイルをコピー [shutil.copy(filepath, foldername) for filepath in path ]
(補足)
ZIP形式のフォーマットについてはhttps://sentinel.esa.int/web/sentinel/user-guides/sentinel-2-msi/data-formatsを参照してください。
Lesson 8Chapter 4.5
複数のバンドを読み込む
衛星画像は、色の波長ごとに分かれたファイルとして構成されています。色の波長の区分のことを「バンド」と言います。Sentinel-2の場合、1~13のバンドがあり、次の図のように対応しています。たとえばバンド2は青、バンド3は緑、バンド4は赤です。それより上のバンド赤外線の領域で、人間の目には見えない範囲です。
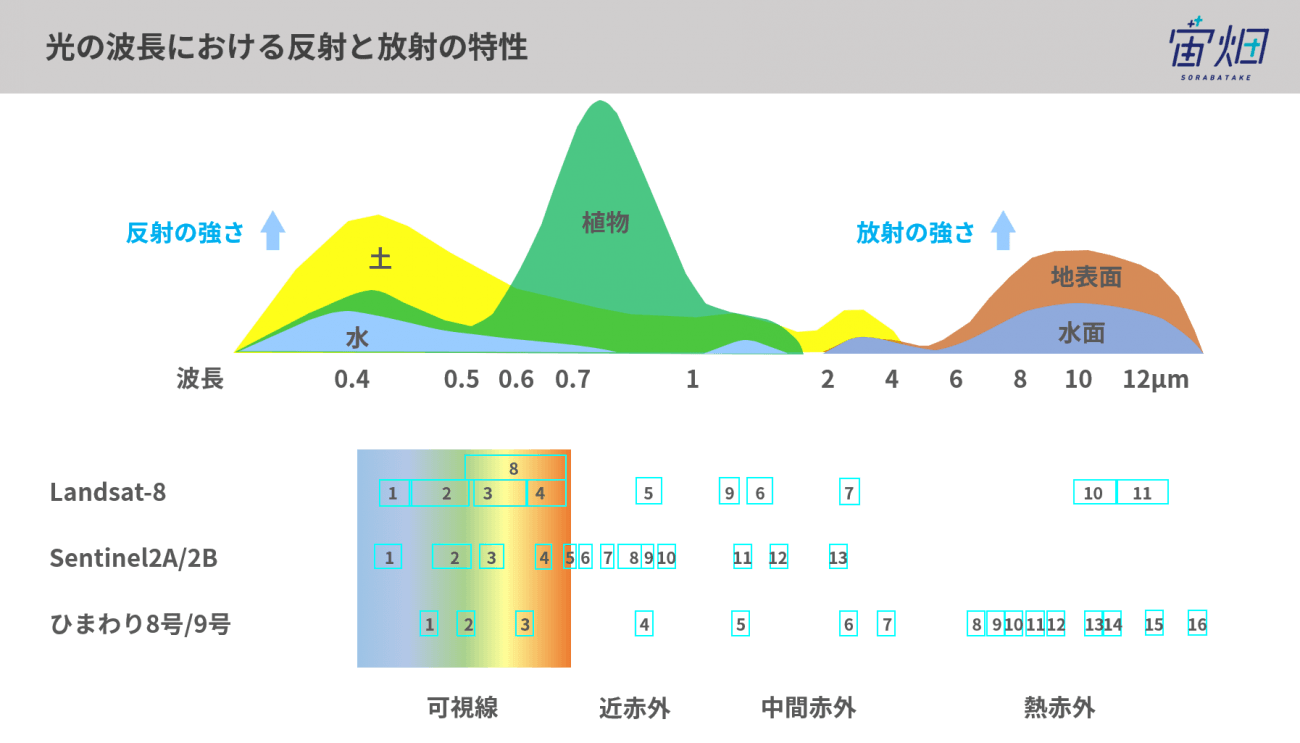
(出典元:光の波長って何? なぜ人工衛星は人間の目に見えないものが見えるのか | 宙畑)
OpenCVで読み込む
実際にOpenCVで読み込んでみましょう。R10mフォルダに含まれている、それぞれのバンドに対応する画像は、次の命名規則をとるJPEG2000形式のデータです。
T54SUE_年月日T時分秒__Bバンド番号_10m.jp2
OpenCVでは、imreadでJPEG2000形式のデータを読み込めます。
すぐあとに説明しますが、カラー画像にするためには、光の三原色に対応するバンド2(青)・バンド3(緑)・バンド4(赤)を組み合わせます。さらに、近赤外線の情報であるバンド8も利用します。
まずは、それぞれのバンドの画像を読み込んでみましょう。ファイルサイズが大きいため、読み込みには、少し時間がかかります。
# cv2.imread()でB02,03,04,08のデータをそのままの画像形式で読み込む b02 = cv2.imread('./R10m/T54SUE_20191214T013041_B02_10m.jp2', cv2.IMREAD_UNCHANGED) b03 = cv2.imread('./R10m/T54SUE_20191214T013041_B03_10m.jp2', cv2.IMREAD_UNCHANGED) b04 = cv2.imread('./R10m/T54SUE_20191214T013041_B04_10m.jp2', cv2.IMREAD_UNCHANGED) b08 = cv2.imread('./R10m/T54SUE_20191214T013041_B08_10m.jp2', cv2.IMREAD_UNCHANGED)
データの形状とデータ型を確認することで、読み込めたかどうかを確認しておきます。画像のサイズは10980×10980、画素はuint16であり16ビットで構成されている(0~65535までの値)であることがわかります。
# B02,03,04,08のデータの形状とデータの型を調べる
print(b02.shape)
print(b02.dtype)
print(b03.shape)
print(b03.dtype)
print(b04.shape)
print(b04.dtype)
print(b08.shape)
print(b08.dtype)
出力結果:
(10980, 10980) uint16 (10980, 10980) uint16 (10980, 10980) uint16 (10980, 10980) uint16
Lesson 8Chapter 4.6
画像の前処理
こうして得られた、それぞれのバンドの画像を合成してカラー画像を作ります。
ここではまず、B=バンド2・G=バンド3・R=バンド4のデータを設定して、BGR形式の画像を作ります。
(補足)
JPEG2000はuint16(0~65535の範囲)、OpenCVのBRG形式はuint8(0~255)なので、下記のプログラムでは、256で割っている点に注意してください。
# B02,03,04を合成したBGR形式の画像を用意する out_image_bgr = np.zeros((10980, 10980, 3), dtype=np.uint8) # それぞれ256で割ることで16bitから8bitのデータに変換。その上で代入する out_image_bgr[:, :, 0] = b02 // 256 out_image_bgr[:, :, 1] = b03 // 256 out_image_bgr[:, :, 2] = b04 // 256 # この画像を表示してみる plt.imshow(cv2.cvtColor(out_image_bgr, cv2.COLOR_BGR2RGB))
出力結果:

実際の結果を確認するとわかるように、画像はほぼ黒い状態です。これはデータの最大値が小さすぎるためです。下記のようにしてデータの最大値を調べてみると、30前後しかありません。8ビットの幅は256なので、こうした小さな値では、ほとんど色がわかりません。
# B,G,Rの最大値を調べる print(out_image_bgr[0].max()) print(out_image_bgr[1].max()) print(out_image_bgr[2].max())
出力結果:
23
19
17
ヒストグラムでも確認してみましょう。すべての色の成分が値の小さい範囲に集中していることがヒストグラムからも確認できます。
# BGR(青緑赤)のヒストグラムを重ねて表示 # 青の成分 img_hist = cv2.calcHist([out_image_bgr],[0],None,[256],[0,256]) plt.plot(img_hist, color="blue") # 緑の成分 img_hist = cv2.calcHist([out_image_bgr],[1],None,[256],[0,256]) plt.plot(img_hist, color="green") # 赤の成分 img_hist = cv2.calcHist([out_image_bgr],[2],None,[256],[0,256]) plt.plot(img_hist, color="red")
出力結果:

コントラストを強調する(画像を明るくする)
画像が見えるようにするには、「ガンマ補正」と「CLAHEによる明度の平坦化」を実施します。
(1)ガンマ補正
ガンマ補正をするための関数を下記に示します。
# ガンマ補正を行う関数を定義 def gamma_correction(image, gamma): # 整数型で2次元配列を作成[256,1] lookup_table = np.zeros((256, 1), dtype = 'uint8') for i in range(256): # γテーブルを作成 lookup_table[i][0] = 255 * (float(i) / 255) ** (1.0/gamma) # lookup Tableを用いて配列を変換 return cv2.LUT(image, lookup_table)
(2)CLAHEによる明度の平坦化
CLAHEについては、「3.2.3」で説明しました。ここでは下記のようにグリッドサイズを3×3としたclaheを使うことにします。
# CLAHE clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(3, 3))
上記のgamma_correctionとclaheを使ってコントラストを強調します。
まずは、ガンマ補正を実行します。
# ガンマ補正を実施 out_image = gamma_correction(out_image_bgr, 3.0)
続いて、明度の平坦化を実行します。
# CLAHEを使ってV(明度)を平坦化 out_image_hsv2 = cv2.cvtColor(out_image, cv2.COLOR_BGR2HSV) out_image_hsv2[:, :, 2] = clahe.apply(out_image_hsv2[:, :, 2])
生成した画像を表示してみます。衛星画像がカラー画像で表示されました。
# この画像を表示してみる
out_image_bgr2 = cv2.cvtColor(out_image_hsv2, cv2.COLOR_HSV2BGR)
plt.imshow(cv2.cvtColor(out_image_bgr2, cv2.COLOR_BGR2RGB))

ヒストグラムで確認してみましょう。補正の効果が現れていることが確認できます。
# BGR(青緑赤)のヒストグラムを重ねて表示 # 青の成分 img_hist = cv2.calcHist([out_image_bgr2],[0],None,[256],[0,256]) plt.plot(img_hist, color="blue") # 緑の成分 img_hist = cv2.calcHist([out_image_bgr2],[1],None,[256],[0,256]) plt.plot(img_hist, color="green") # 赤の成分 img_hist = cv2.calcHist([out_image_bgr2],[2],None,[256],[0,256]) plt.plot(img_hist, color="red")
出力結果:

この画像をファイルとして保存しておきましょう。out_image_bgr.pngというファイル名で保存します。
# 画像を保存する cv2.imwrite('out_image_bgr.png', out_image_bgr2)
その他の前処理
このチャプターで説明してきたように、衛星画像は基本的にバンドごとで用意されています。機械学習やディープラーニングなどの学習データとして使う場合は、ガンマ補正をかけたり明度の平坦化をしたりして、調整する必要があります。
ときにはさらに、次のような前処理も必要になるかも知れません。これらについては、すでに説明しているので、必要に応じて実施してください。
- ノイズの除去
- 画像のリサイズ
- エッジの検出、膨張・収縮
- 平行移動や回転、反転
また衛星データの仕様によっては、さらに前段の前処理が必要になることもあります。詳細については、下記のページを参考にしてください。
(補足)必要な部分のみを切り取る方法
ダウンロードできる画像は、queryの引数に渡したGeoJSONデータなどの領域が含まれる範囲であり、その領域で切り取られた画像ではありません。その領域だけを取り出したいのであれば、生成された画像に対して、さらに切り取る必要があります。
切り取り処理をするには、次のようにします。
restrioを使って衛星データを読み込む- 衛星データから幅・高さ・EPGSコードなど必要な情報を取得する
- RGBデータと2で取得したデータを含んだTIFF形式の画像を作成・保存する
- GoPandasで該当部分のgeojsonファイルを読み込む
- 切り抜き処理をする
- 切り抜いたデータをTIFFとして保存する
以下にその具体的な手順を示します。
(1)ライブラリのインポート
必要なライブラリをインポートします。
# 必要なライブラリのインポート import rasterio as rio from rasterio.plot import show from rasterio.mask import mask import geopandas as gpd
(2)データを読み込む
データを読み込みます。ここではバンド2のデータを読み込む例を示します。
# バンド2のデータをrasterioで開く b02rst = rio.open('./R10m/T54SUE_20191214T013041_B02_10m.jp2') print(b02rst.count) # バンド数(バンド2の1種類のみなので1となる) print(b02rst.width) # データの幅 print(b02rst.height) # データの高さ print(b02rst.transform) # データの形が定義されたもの(このあと使いますが深く知る必要ありません) print(b02rst.crs) # EPGSコード
出力結果:
1 10980 10980 | 10.00, 0.00, 300000.00| | 0.00,-10.00, 4000020.00| | 0.00, 0.00, 1.00| EPSG:32654
データの種類を確認しておきます。uint16です。
print(b02rst.dtypes)
出力結果:
('uint16',)
(3)TIFF形式画像の作成・保存をする
TIFF形式の画像を作成して保存します。
# TIFF形式の画像を作成・保存する with rio.open('tokyo_bay.tiff', 'w', driver='GTiff', width=b02rst.width, height=b02rst.height, count=3, # R,G,Bの情報を持たせるので3にする crs=b02rst.crs, transform=b02rst.transform, dtype='uint8') as rst_rgb: rst_rgb.write(out_image_bgr2[:, :, 2], 1) # R rst_rgb.write(out_image_bgr2[:, :, 1], 2) # G rst_rgb.write(out_image_bgr2[:, :, 0], 3) # B rst_rgb.close()
(4)GeoJSONファイルをEPGSに変換する
GeoJSONファイルをGetPandasとして読み込みます。さらに、EPGSの仕様に適した形式へ変換します。
# GeoJSONファイルをGeoPandasで読み込む gp_tokyo_bay = gpd.read_file('tokyo_bay.geojson') # EPGSの仕様に適した形式へGeoJSONデータを変換する gp_tokyo_bay_opt = gp_tokyo_bay.to_crs({'init': b02rst.crs}) # このあと必要なデータの確認 print(gp_tokyo_bay_opt.geometry)
出力結果:
0 POLYGON ((382371.615 3925958.289, 396327.190 3... Name: geometry, dtype: geometry
(5)切り抜く
下記のようにして、切り抜きます。
# 切り抜かれたデータを入れる変数(ひとまずNoneで初期化) out_image = None # 切り抜かれたデータの幅・高さなどの情報を入れる変数(ひとまずNoneで初期化) out_meta = None # 画像の切り抜き処理 with rio.open('tokyo_bay.tiff') as src: # 画像を切り抜いてout_imageに入れる out_image, out_transform = rio.mask.mask(src, gp_tokyo_bay_opt.geometry, crop=True) # 画像の情報を複製してout_metaに入れる out_meta = src.meta.copy() # out_metaを切り抜いたあとの画像の情報で更新する out_meta.update({'driver': 'GTiff', 'height': out_image.shape[1], 'width': out_image.shape[2], 'transform': out_transform}) src.close()
(6)ファイルとして保存する
最後にファイルとして保存します。
# 切り抜いた画像を保存 with rio.open('out_image.tiff', 'w', **out_meta) as dest: dest.write(out_image) dest.close()
このチャプターの学習内容は以上です。このあとは、より応用的な実習を行います。
Lesson
8Chapter 5
OpenCVを用いた演習
Lesson 8Chapter 5.1
学習の目標
このチャプターでは、衛星データを用いた2つの演習をします。
Lesson 8Chapter 5.2
演習1:浜辺の侵食の様子を確認する(1)
最初の演習は、2つの衛星画像を比較するものです。
海と陸との境界線である海岸線は、少しずつ時間をかけて変化しています。理由は複雑です。気候変動や私たち人間の開発、その他様々な要因が、潮の流れや土砂の滞留に作用して、海岸線を変化させています。
海岸線の変化は、漁業や観光業などに影響を与えます。例えば近年、千葉県の九十九里浜では、浜辺の侵食が問題となっています。
https://www.pref.chiba.lg.jp/kasei/kaigan/kujukurihama-sinsyokutaisaku-keikaku.html
衛星データを使うと海岸線を高い精度で得ることが出来ます。異なる時期の海岸線の変化を継続的に確認することで、侵食等の可視化が可能となります。これは海岸線の変化の予測や、侵食を防止するための効果的な施策に役立ちます。
今回の演習では、異なる時期の2つの九十九里浜の衛星データを取得し、海岸線を比較します。演習は次の順番で行います。
- 衛星データを取得する
- 衛星データをプログラムに取り込む
- クラスタリングで陸と水域を分類する
- 海岸線を取得する
- 結果を確認する
1. 衛星データを取得する
必要なライブラリをインポートします。
# 必要なライブラリのインポート import matplotlib.pyplot as plt import numpy as np from sentinelsat import SentinelAPI, read_geojson, geojson_to_wkt import cv2 import rasterio as rio from rasterio.plot import show from rasterio.mask import mask import geopandas as gpd import shutil import os %matplotlib inline
ユーザー認証を行い、APIを利用できるようにします。
# 認証 user = 'ユーザー名' passwd = 'パスワード' api = SentinelAPI(user, passwd, 'https://scihub.copernicus.eu/dhus')
読み込み範囲を指定します。ここでは九十九里浜近辺の範囲を示した以下のGeoJSONファイルを使用します。下記のファイルをダウンロードし、Jupyter Notebookのファイルと同じフォルダに保存してください。
GeoJSONファイルを読み込みます。
# 九十九里浜周辺が指定されたGeoJSONのデータを読み込む footprint_geojson = geojson_to_wkt(read_geojson('./kujukuri_hama.geojson'))
この演習では、2019年2月中旬と2021年1月中旬の海岸線を比較します。
はじめに、2019年2月10日~2019年2月21日の衛星データを取得します。
# 2019年2月中旬頃のSentinel-2のデータを取得 products_previous = api.query(footprint_geojson, date = ('20190210', '20190221'), #取得希望期間の入力 platformname = 'Sentinel-2', processinglevel = 'Level-2A', cloudcoverpercentage = (0,100)) #被雲率(0%〜100%) # 取得したデータ数を表示 len(products_previous)
結果は以下のとおりです。該当する衛星データは4つあります。
出力結果:
4
この中から、もっとも雲が少ないデータを使います。衛星データを被雲率(cloudcoverpercentage)の少ない順番で並べ替えます。
# 被雲率の昇順で並び替え products_prev_gdf = api.to_geodataframe(products_previous) products_prev_gdf_sorted = products_prev_gdf.sort_values(['cloudcoverpercentage'], ascending=[True]) products_prev_gdf_sorted
出力結果:

1行目がもっとも雲が少ない衛星データになります。ここからダウンロードに必要な情報を取得します。
出力結果:
f95018e3-1e77-46a5-a363-8bc13c64b69f
S2B_MSIL2A_20190212T012759_N0211_R074_T54SVE_20190212T052030
- 「f95018e3-1e77-46a5-a363-8bc13c64b69f」:indexの値です。apiで衛星データを取得する際に使用します。
- 「S2B_MSIL2A_20190212T012759_N0211_R074_T54SVE_20190212T052030」:titleの値です。衛星データはZIP形式の圧縮ファイルになっています。ファイル名はtitleの値で拡張子はzipです。圧縮ファイルを解凍するとtitleの末尾に「.SAFE」という文字を付与したフォルダ名で展開されます。
それではapiを使って衛星データをダウンロードしましょう。併せてダウンロードした圧縮ファイルの解凍も行います。
# 衛星データのダウンロード api.download(index) # ダウンロードしたファイルの解凍 shutil.unpack_archive(title+'.zip')
解凍した衛星データから、必要なファイルを「R10m_2019」フォルダにコピーします。具体的には衛星データの[GRANULE]→[L2A_T54SUE_AXXXXXXXXXXXXX](XXXXXXはそれぞれ異なる名前)→[IMG_DATA]配下にある
[R10m] フォルダの中にある全てのファイルを「R10m_2019」フォルダにコピーします。
まずは衛星データの必要なファイル名をリストで返す関数を定義します。
# 衛星データのR10mフォルダのファイル名をリストで返す関数 def strpjp2(productTitle): path = str(productTitle) + '.SAFE/GRANULE' files = os.listdir(path) pathA = str(productTitle) + '.SAFE/GRANULE/' + str(files[0]) files2 = os.listdir(pathA) pathB = str(productTitle) + '.SAFE/GRANULE/' + str(files[0]) +'/' + str(files2[1]) +'/R10m' files3 = os.listdir(pathB) filepath = [] for file in files3: filepath.append(pathB+'/'+file) return(sorted(filepath))
上記の関数を使って衛星データからコピーするファイル名を取得し、フォルダの作成、ファイルのコピーを行います。
# 衛星データのファイル名をリストで取得 path = strpjp2(title) # 作成するフォルダ名 foldername = 'R10m_2019' # フォルダが存在していたら削除 if os.path.exists(foldername): shutil.rmtree(foldername) # フォルダを作成 os.makedirs(foldername,exist_ok=True) # 衛星データのファイルをコピー [shutil.copy(filepath, foldername) for filepath in path ]
出力結果:
['R10m_2019\\T54SVE_20190212T012759_AOT_10m.jp2',
'R10m_2019\\T54SVE_20190212T012759_B02_10m.jp2',
'R10m_2019\\T54SVE_20190212T012759_B03_10m.jp2',
'R10m_2019\\T54SVE_20190212T012759_B04_10m.jp2',
'R10m_2019\\T54SVE_20190212T012759_B08_10m.jp2',
'R10m_2019\\T54SVE_20190212T012759_TCI_10m.jp2',
'R10m_2019\\T54SVE_20190212T012759_WVP_10m.jp2']
2021年1月中旬画像の取得
同様にして、2021年1月10日~2021年1月21のデータも取得します。
# 2021年1月中旬頃のSentinel-2のデータを取得 products_recently = api.query(footprint_geojson, date = ('20210110', '20210121'), #取得希望期間の入力 platformname = 'Sentinel-2', processinglevel = 'Level-2A', cloudcoverpercentage = (0,100)) #被雲率(0%〜100%) # 取得したデータ数を表示 len(products_recently)
結果は以下のとおりです。該当する衛星データは5つあります。
出力結果:
5
衛星データを被雲率(cloudcoverpercentage)の少ない順番で並べ替えます。
# 被雲率の昇順で並び替え products_rcnt_gdf = api.to_geodataframe(products_recently) products_rcnt_gdf_sorted = products_rcnt_gdf.sort_values(['cloudcoverpercentage'], ascending=[True]) products_rcnt_gdf
出力結果:

先ほどと同様に、1行目から必要な情報を取得します。
# 観測画像のインデックス:apiを使ったダウンロードに使用 index = products_rcnt_gdf_sorted.index[0] print(index)# 観測画像のtitle:ファイル名、フォルダ名に使用 title = products_rcnt_gdf_sorted.iloc[0]['title'] print(title)
以下の出力結果をそのままブラウザのURL欄にコピペすると、衛星データをダウンロードできます。
出力結果:
5da555fb-8281-4ba9-b360-6bc1f2e46594 S2A_MSIL2A_20210114T012011_N0214_R031_T54SVE_20210114T041142
apiを使って衛星データをダウンロードします。併せてダウンロードした圧縮ファイルの解凍も行います。
# 衛星データのダウンロード api.download(index) # ダウンロードしたファイルの解凍 shutil.unpack_archive(title+'.zip')
衛星データからコピーするファイル名を取得し、フォルダの作成、ファイルのコピーを行います。
# 衛星データのファイル名をリストで取得 path = strpjp2(title) # 作成するフォルダ名 foldername = 'R10m_2021' # フォルダが存在していたら削除 if os.path.exists(foldername): shutil.rmtree(foldername) # フォルダを作成 os.makedirs(foldername,exist_ok=True) # 衛星データのファイルをコピー [shutil.copy(filepath, foldername) for filepath in path ]
出力結果:
['R10m_2021\\T54SVE_20210114T012011_AOT_10m.jp2',
'R10m_2021\\T54SVE_20210114T012011_B02_10m.jp2',
'R10m_2021\\T54SVE_20210114T012011_B03_10m.jp2',
'R10m_2021\\T54SVE_20210114T012011_B04_10m.jp2',
'R10m_2021\\T54SVE_20210114T012011_B08_10m.jp2',
'R10m_2021\\T54SVE_20210114T012011_TCI_10m.jp2',
'R10m_2021\\T54SVE_20210114T012011_WVP_10m.jp2']
フォルダ構成が以下のようになっていることを確認しましょう。ソースコードを記述しているノートブックと同じ階層に「kujukuri_hama.geojson」ファイルと「R10m_2019」フォルダ、「R10m_2021」フォルダがあり、それぞれのフォルダに、演習で使用する衛星データが格納されています。

2. 衛星データをプログラムに取り込む
衛星データをPythonのプログラムに取り込みます。このように複数のデータを比較する場合、データを管理するクラスを作成しておくと便利です。今回は以下のようなクラスを作成します。
class Region: # コンストラクタ # pathの例 :'./R10m_2019/T54SVE_20190212T012759_{}_10m.jp2' # bandsの例:['B02','B03','B04','B08','AOT','TCI','WVP'] # B02青、B03緑、B04赤、B08近赤外線は必須 def __init__(self, path, bands=['B02','B03','B04','B08']): self.path = path self.bands = bands self.dataset = self._load_satellite_data(path, bands) # 衛星データを読み込んで辞書として返す def _load_satellite_data(self, path, bands): return {b:(rio.open(path.format(b)).read())[0] for b in bands} # 領域を切り抜いてreginに代入する def set_region(self, geojson_file): self.region = self._get_region(geojson_file, self.path, self.bands) # 領域を切り抜いて辞書として返す def _get_region(self, geojson_file, path, bands): # GeoJSONファイルをGeoPandasで読み込む gpd1 = gpd.read_file(geojson_file) # EPGSの仕様に適した形式へGeoJSONデータを変換する gpd1_crs = gpd1.to_crs({'init': rio.open(path.format('B02')).crs}) _region = {} # 画像を切り抜いてout_imageに入れる for b in bands: img, _ = rio.mask.mask(rio.open(path.format(b)), gpd1_crs.geometry, crop=True) _region[b] = img[0] return _region # ガンマ補正を行う関数 def _gamma_correction(self, image, gamma=3.0): # 整数型で2次元配列を作成[256,1] lookup_table = np.zeros((256, 1), dtype = 'uint8') for i in range(256): # γテーブルを作成 lookup_table[i][0] = 255 * (float(i) / 255) ** (1.0/gamma) # lookup Tableを用いて配列を変換 return cv2.LUT(image, lookup_table) # 与えられたデータをもとにカラー画像を返す def get_rgb_image(self, dataset): # B02,03,04を合成したBGR形式の画像を用意する bgr = np.zeros((dataset['B02'].shape[0], dataset['B02'].shape[1], 3), dtype=np.uint8) for i, b in enumerate(self.bands[:3]): bgr[:, :, i] = dataset[b] // 256 # HSV形式に変換する hsv = cv2.cvtColor(bgr, cv2.COLOR_BGR2HSV) # V(明度)をB08のデータで置き換える hsv[:, :, 2] = dataset['B08'] // 256 # Vを置き換えたデータを再びBGR形式に置き換える rgb = cv2.cvtColor(hsv, cv2.COLOR_HSV2RGB) # ガンマ補正を実施 return self._gamma_correction(rgb)
このクラスのオブジェクトは以下の変数と関数で構成されます。「後で追加」と書いている変数は、上記のソースコードには定義していないが以降のソースコードで追加される変数です。
Regionクラス
- 変数
- path:ファイルパス
- bands:バンドを保持するリスト
- dataset:衛星データを保持する辞書
- region:GeoJSONに対応する領域を保持する辞書
- region_reshaped:クラスタリング用に2次元へreshapeした領域データ(後で追加)
- region_predict:クラスタリングした結果(後で追加)
- region_blurred:クラスタリング結果にガウスフィルタを適用したもの(後で追加)
- region_edge:エッジ(後で追加)
- 関数
- init:コンストラクタ
- set_region:領域を切り抜いてself.reginに代入する
- get_rgb_image:与えられたデータをもとにカラー画像を返す
- 内部関数(このオブジェクトの中でのみ利用される関数)
- _load_satellite_data:[内部関数]衛星データを読み込んで辞書として返す
- _get_region:領域を切り抜いて辞書として返す
- _gamma_correction:ガンマ補正をする関数
Regionクラスのソースコードについて説明します。
# コンストラクタ # pathの例:'./R10m_2019/T54SVE_20190212T012759_{}_10m.jp2' # bandsの例:['B02','B03','B04','B08','AOT','TCI','WVP'] # B02青、B03緑、B04赤、B08近赤外線は必須 def __init__(self, path, bands=['B02','B03','B04','B08']): self.path = path self.bands = bands self.dataset = self._load_satellite_data(path, bands)
クラスを実体化してオブジェクトにするコンストラクタは、pathとbandsを引数として取ります。bandsは省略可能です。
- path:衛星データのファイル名を相対パスで指定します。ファイル名のバンドによって変わる部分を
{}としています - bands:当オブジェクトで保持する衛星データのバンドを指定します。この衛星データを使ってクラスタリングを行います。初期値で4つのバンドを指定していますが増やすことも可能です
# 衛星データを読み込んで辞書として返す def _load_satellite_data(self, path, bands): return {b:(rio.open(path.format(b)).read())[0] for b in bands} # 領域を切り抜いてreginに代入する def set_region(self, geojson_file): self.region = self._get_region(geojson_file, self.path, self.bands)
Regionオブジェクトでは、衛星データや領域を辞書型で保持します。以下のようなイメージです。
{
'B02': B02に対応した衛星データ,
'B03': B03に対応した衛星データ,
'B04': B04に対応した衛星データ, ...
}
GeoJSONファイルを使った領域の切り抜き方、ガンマ補正やカラー画像の作成については既知の内容ですので説明は省略します。
それでは、衛星データを取得しましょう。衛星データを管理するオブジェクトを作成し、regionリストに追加します。以降のプログラムでは、それぞれのオブジェクトに対して同じ処理を行うため、リストで保持しておくとプログラムを簡潔に書くことができます。
# 衛星データの取得 region = [] region.append(Region('./R10m_2019/T54SVE_20190212T012759_{}_10m.jp2')) region.append(Region('./R10m_2021/T54SVE_20210114T012011_{}_10m.jp2'))
次にGeoJSONファイルに対応した領域を取得します。
# 領域の取得 for r in region: r.set_region('kujukuri_hama.geojson')
カラー画像で表示してみましょう。
2019年(衛星データ全体)
plt.figure(figsize=(10,10)) plt.imshow(region[0].get_rgb_image(region[0].dataset))

2021年(衛星データ全体)
plt.figure(figsize=(10,10)) plt.imshow(region[1].get_rgb_image(region[1].dataset))

2019年(GeoJSONで切り出した領域)
plt.figure(figsize=(10,10)) plt.imshow(region[0].get_rgb_image(region[0].region))

2021年(GeoJSONで切り出した領域)
plt.figure(figsize=(10,10)) plt.imshow(region[1].get_rgb_image(region[1].region))

Lesson 8Chapter 5.3
3. クラスタリングで陸と水域を分類する
領域のデータを、クラスタリングによって陸と水域に分類します。領域のデータはバンド毎に(領域の高さ x 領域の幅)の2次元の形状で保持しています。これを「バンド数
X 領域のピクセル数」のNumpy配列に変換します。「領域のピクセル数=領域の高さ x
領域の幅」です。これをさらに転置(行列入れ替え)して「領域のピクセル数 X
バンド数」の形状にします。結果はRegionオブジェクトのregion_reshapedに格納します。
# クラスタリング用のデータを作成してオブジェクトに追加 for r in region: # 領域の辞書をNumpy配列に変換する tmp = np.array([r.region[b] for b in r.bands]) print(tmp.shape) # 2次元にし、転置する(行と列を入れ替える) r.region_reshaped = tmp.reshape(len(tmp),-1).T print(r.region_reshaped.shape)
実行結果は以下のとおりです。
出力結果:
(4, 4280, 3159)
(13520520, 4)
(4, 4280, 3159)
(13520520, 4)
データが準備できたらクラスタリングを行います。今回はk-means++法というアルゴリズムでクラスタリングを行います。k-means法はクラスタリングの代表的なアルゴリズムで、グループ毎に中心点(シード)を置き、それにデータを所属させることでクラスタリングを行う方法です。以下のサイトでk-means法によるクラスタリングの方法を視覚的に確認できます。
ただし、k-means法のシードの初期値はランダムであるため、シードが偏って置かれた場合、クラスタリングが上手く行われないという問題点があります。そこで一般的にはk-means法を改良したk-means++法がよく使われます。k-means++法はシードの初期値をランダムではなく、なるべく離れるように置くことで、偏りを防ぎます。
まずは、必要なライブラリを読み込みます。
# 必要なライブラリの読込 from sklearn.cluster import KMeans
データの特徴をクラスタリングを行うプログラム(モデル)に覚えさせることを「学習」と言います。学習用に2019年と2021年を結合したデータを用意します。
# 2019年と2021年を結合したデータで学習を実施する train = np.append(region[0].region_reshaped, region[0].region_reshaped, axis=0) train.shape
実行結果は以下のとおりです。
出力結果:
(27041040, 4)
学習を実施します。今回は陸と水域の2つに分類するため、クラスタ数「n_clusters」は2にします。
# 学習の実施 model = KMeans(n_clusters=2, init='k-means++', n_init=10) model.fit(train)
実行結果は以下のとおりです。モデルの設定値(パラメータ)が表示されます。
出力結果:
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=2, n_init=10, n_jobs=None, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
学習したモデルを使い、データを分類します。分類結果は(領域の高さ x
領域の幅)の2次元の形状にしてRegionオブジェクトのregion_predict変数に格納します。
# 領域の大きさを取得 height = region[0].region['B02'].shape[0] width = region[0].region['B02'].shape[1] print(height, width) # クラスタリングを実施し、結果をregion_predictに代入する for r in region: r.region_predict = model.predict(r.region_reshaped).reshape(height, width)
実行結果は以下のとおりです。
出力結果:
4280 3159
クラスタリングした結果を確認しましょう。
2019年
plt.figure(figsize=(10,10)) plt.imshow(region[0].region_predict, cmap="tab20_r")

2021年
plt.figure(figsize=(10,10)) plt.imshow(region[1].region_predict, cmap="tab20_r")

最後に画像のノイズを除去します。ノイズ除去で多く用いられているガウスフィルタを使用します。ノイズ除去した結果はRegionオブジェクトのregion_blurred変数に格納します。
for r in region: tmp = r.region_predict.astype("uint8") r.region_blurred = cv2.GaussianBlur(tmp, (51,51), 0)
ガウスフィルタを適用した結果を確認しましょう。
2019年
plt.figure(figsize=(10,10)) plt.imshow(region[0].region_blurred, cmap="tab20_r")

2021年
plt.figure(figsize=(10,10)) plt.imshow(region[1].region_blurred, cmap="tab20_r")

4. 海岸線を取得する
クラスタリングした結果のエッジを抽出することで、海岸線を取得することが出来ます。
# エッジ膨張用 kernel = np.ones((3, 3)) / 9.0 for r in region: tmp = cv2.Canny(r.region_blurred, 2, 5).astype("float") # エッジを膨張させる tmp = cv2.dilate(tmp, kernel) tmp[tmp == 0] = np.nan r.region_edge = tmp
ソースコードについて説明します。
tmp = cv2.Canny(r.region_blurred, 2, 5).astype("float")
エッジの抽出には前に取り上げたCanny法を使用します。
# エッジを膨張させる
tmp = cv2.dilate(tmp, kernel)
今回は、併せてエッジの膨張も行っています。エッジの膨張は前に取り上げたdilateを使っています。
tmp[tmp == 0] = np.nan
エッジ以外のピクセルにはNaNを設定します。これによりエッジの画像を表示した際にエッジ以外の場所を透過させることができます。
エッジの抽出結果を確認しましょう。カラー画像に重ね合わせて表示します。
2019年
# 検出したエッジの画像を表示 plt.figure(figsize=(15,15)) plt.imshow(region[0].get_rgb_image(region[0].region)) plt.imshow(region[0].region_edge, cmap="Set3_r")

2021年
# 検出したエッジの画像を表示 plt.figure(figsize=(15,15)) plt.imshow(region[1].get_rgb_image(region[1].region)) plt.imshow(region[1].region_edge, cmap="Set1")

とてもきれいにエッジが抽出されていることが確認できますね。
5. 結果を確認する
最後に2019年と2021年の海岸線を重ね合わせて変化を確認しましょう。なお、savefig関数で結果を画像として保存できます。
# 検出したエッジの画像を表示 plt.figure(figsize=(15,15)) plt.imshow(region[0].get_rgb_image(region[0].region)) plt.imshow(region[0].region_edge, cmap="Set3_r") plt.imshow(region[1].region_edge, cmap="Set1") # 結果を画像として保存する # plt.savefig('edge.png')

結果のX軸、Y軸の値はピクセル数です。この値を参考にして、いくつかの領域を抜き出して拡大してみましょう。
# 検出したエッジの画像を表示 plt.figure(figsize=(10,10)) plt.imshow(region[0].get_rgb_image(region[0].region)[1300:2100, 500:1500]) plt.imshow(region[0].region_edge[1300:2100, 500:1500], cmap="Set3_r") plt.imshow(region[1].region_edge[1300:2100, 500:1500], cmap="Set1")

# 検出したエッジの画像を表示 plt.figure(figsize=(10,10)) plt.imshow(region[0].get_rgb_image(region[0].region)[500:1300, 1000:2000]) plt.imshow(region[0].region_edge[500:1300, 1000:2000], cmap="Set3_r") plt.imshow(region[1].region_edge[500:1300, 1000:2000], cmap="Set1")

# 検出したエッジの画像を表示 plt.figure(figsize=(10,10)) plt.imshow(region[0].get_rgb_image(region[0].region)[0:800, 2158:3158]) plt.imshow(region[0].region_edge[0:800, 2158:3158], cmap="Set3_r") plt.imshow(region[1].region_edge[0:800, 2158:3158], cmap="Set1")

# 検出したエッジの画像を表示 plt.figure(figsize=(10,10)) plt.imshow(region[0].get_rgb_image(region[0].region)[3479:4279, 0:1000]) plt.imshow(region[0].region_edge[3479:4279, 0:1000], cmap="Set3_r") plt.imshow(region[1].region_edge[3479:4279, 0:1000], cmap="Set1")

このように衛星データとクラスタリング、Canny法によるエッジ検出を組み合わせることで、とてもきれいに海岸線を抽出できました。
今回作成したRegionクラスには簡単にバンドを追加できます。バンドを追加してクラスタリングの性能が向上するか試してみましょう。また、他の地域の衛星データを使った海岸線や水域(湖や河川など)の抽出にもチャレンジしてみましょう。なるべく雲がかかっていない衛星データを選ぶようにすると、より良好な結果が得られます。
Lesson 8Chapter 5.4
演習2:植生の状態から道路を抽出する
以前より、都市化に伴う自然環境の破壊が問題視されています。たとえば、東南アジアではプランテーション農園による単一作物の大規模栽培が進められており、それに伴い道路網も整備されています(例:Googleマップのカリマンタン島上空の様子)。そこで、二つ目の演習では、植物による光の反射の特徴から道路を抽出してみます。
衛星データは光の反射のデータを持っているため、地表のどの箇所の植生がよいか、悪いかを確認できます。例えば、人工物が作られている部分は、植生の状態が悪いと言えます。そこで、ここでは植生の良し悪しを計測して、人工物である道路を抽出します。
植生指標データNVDI
植物の育成の良し悪しを計測する代表的な植生指標として、NVDI(Normalized Difference Vegetation Index:正規化植生指標)という指標があります。これは衛星データの「可視域赤(R)」の値と、「近赤外線域(NIR)」の値から、次の計算式で求められます。
NVIR = (NIR - R) / (NIR + R)
NVDIの値は -1~+1 の範囲です。今回は、これを0~200の整数に変換した値を用いて抽出を試みます(8ビットデータに適合するので、図示する場合に便利です)。
植生指標データ = (NDVI + 1.0) * 100
以下の演習では、カリマンタン島の衛星データを取得してNDVIを算出し、その値でグレースケール画像を作成します。そうすることで、色の濃淡で植生の状態を可視化できます。
読み込み範囲の指定
まずは、読み込む範囲のGeoJSONを用意します。ここではカリマンタン島のとある場所を選択するGeoJSONを下記のように用意しました。このファイルをノートブックと同じフォルダに置き、次のプログラムを実行して読み込みます。
# GeoJSONのデータを読み込む kalimantan_geojson = geojson_to_wkt(read_geojson('./kalimantan.geojson'))
参考までに、今回取得したGeoJSONデータは、以下の場所になります (Googleマップが開きます)。
Sentinel-2データの取得
次に、Sentinel-2のデータを取得します。ここでは2020年9月1日~2020年9月20日のデータを取得してみます。4件のデータがあるようです。
# 2020年9月中旬頃のSentinel-2のデータを取得 kalimantan_products = api.query(kalimantan_geojson, date = ('20200901', '20200920'), #取得希望期間の入力 platformname = 'Sentinel-2', processinglevel = 'Level-2A', cloudcoverpercentage = (0,100)) #被雲率(0%〜100%) # 取得したデータ数を表示 len(kalimantan_products)
出力結果:
4
被雲率の昇順での並び替え処理を記述・実行します。
# 被雲率の昇順で並び替え kalimantan_prod_gdf = api.to_geodataframe(kalimantan_products) kalimantan_prod_gdf_sorted = kalimantan_prod_gdf.sort_values(['cloudcoverpercentage'], ascending=[True]) kalimantan_prod_gdf_sorted
出力結果:

# 観測画像のダウンロードURLを表示(表示内容をそのままブラウザのURL欄にコピペで入力) print(kalimantan_prod_gdf_sorted[0]['link'])
出力結果:
https://scihub.copernicus.eu/dhus/odata/v1/Products('2dc72b5f-6469-458a-9a85-254f1f79b397')/$value
このリンクをブラウザで開いてZIP形式ファイルとしてダウンロードします。
ZIP形式ファイルを展開し、[GRANULE]→[L2A_T48PVV_AXXXXXXXXXXXXX](XXXXXXはそれぞれ異なる名前)→[IMG_DATA]→[R10m]フォルダを[R10m_ka]という名前に変更し、このフォルダとそのなかにある画像データを、ノートブックと同じ場所にコピーしておきます。
# 衛星データのダウンロード index = kalimantan_prod_gdf_sorted.index[0] api.download(index) # ダウンロードしたファイルの解凍 title = kalimantan_prod_gdf_sorted.title[0] shutil.unpack_archive(title+'.zip')
画像を確認してみる
まずは、演習1と同様の処理を行い、衛星画像を目で確認してみましょう。処理内容につきましては、演習1の解説内容をご覧ください。
# ガンマ補正を行う関数を定義 def gamma_correction(image, gamma): # 整数型で2次元配列を作成[256,1] lookup_table = np.zeros((256, 1), dtype = 'uint8') for i in range(256): # γテーブルを作成 lookup_table[i][0] = 255 * (float(i) / 255) ** (1.0/gamma) # lookup Tableを用いて配列を変換 return cv2.LUT(image, lookup_table) # CLAHE clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(3, 3))
# ヒストグラムを表示する関数 # 引数:画像、表示する下限値、上限値 def show_hist_bgr(image, range_from=0, range_to=256): # BGR(青緑赤)のヒストグラムを重ねて表示 bins = range_to-range_from # 青の成分 img_hist = cv2.calcHist([image],[0],None,[bins],[range_from,range_to]) plt.plot(img_hist, color="blue") # 緑の成分 img_hist = cv2.calcHist([image],[1],None,[bins],[range_from,range_to]) plt.plot(img_hist, color="green") # 赤の成分 img_hist = cv2.calcHist([image],[2],None,[bins],[range_from,range_to]) plt.plot(img_hist, color="red")
# 衛星データのR10mフォルダのファイル名をリストで返す関数 def strpjp2(productTitle): path = str(productTitle) + '.SAFE/GRANULE' files = os.listdir(path) pathA = str(productTitle) + '.SAFE/GRANULE/' + str(files[0]) files2 = os.listdir(pathA) pathB = str(productTitle) + '.SAFE/GRANULE/' + str(files[0]) +'/' + str(files2[1]) +'/R10m' files3 = os.listdir(pathB) filepath = [] for file in files3: filepath.append(pathB+'/'+file) return(sorted(filepath))
上記の関数を使って衛星データからコピーするファイル名を取得し、フォルダの作成、ファイルのコピーを行います。
# 衛星データのファイル名をリストで取得 path = strpjp2(title) # 作成するフォルダ名 foldername = 'R10m_ka' # フォルダが存在していたら削除 if os.path.exists(foldername): shutil.rmtree(foldername) # フォルダを作成 os.makedirs(foldername,exist_ok=True) # 衛星データのファイルをコピー [shutil.copy(filepath, foldername) for filepath in path ]
# ライブラリのインポート from rasterio import plot band2 = rio.open('./R10m_ka/T49NCB_20200918T024549_B02_10m.jp2') band3 = rio.open('./R10m_ka/T49NCB_20200918T024549_B03_10m.jp2') band4 = rio.open('./R10m_ka/T49NCB_20200918T024549_B04_10m.jp2') # kalimantan_rgb.tiffのファイル名で保存する tcKalimantan = rio.open('./kalimantan_rgb.tiff', 'w', driver='GTiff', width=band4.width, height=band4.height, count=3, crs=band4.crs, transform=band4.transform, dtype=band4.dtypes[0] ) tcKalimantan.write(band2.read(1),3) #blue tcKalimantan.write(band3.read(1),2) #green tcKalimantan.write(band4.read(1),1) #red tcKalimantan.close() # GeoJSONファイルをGeoPandasで読み込む ca_rgb_gpd = gpd.read_file('kalimantan.geojson') # EPGSの仕様に適した形式へGeoJSONデータを変換する ca_rgb_gpd_opt = ca_rgb_gpd.to_crs({'init': band4.crs}) # 切り抜かれたデータを入れる変数(ひとまずNoneで初期化) ca_rgb_image = None # 切り抜かれたデータの幅・高さなどの情報を入れる変数(ひとまずNoneで初期化) ca_rgb_meta = None # 画像の切り抜き処理 with rio.open('./kalimantan_rgb.tiff') as src: # 画像を切り抜いてout_imageに入れる ca_rgb_image, ca_rgb_transform = rio.mask.mask(src, ca_rgb_gpd_opt.geometry, crop=True) # 画像の情報を複製してout_metaに入れる ca_rgb_meta = src.meta.copy() # out_metaを切り抜いたあとの画像の情報で更新する ca_rgb_meta.update({'driver': 'GTiff', 'height': ca_rgb_image.shape[1], 'width': ca_rgb_image.shape[2], 'transform': ca_rgb_transform}) src.close() # 切り抜いた画像を保存 with rio.open('./ca_rgb_image.tiff', 'w', **ca_rgb_meta) as dest: dest.write(ca_rgb_image) dest.close()
# 切り抜いた画像を読み込んで表示 # 画像を開く ka_raster = rio.open("ca_rgb_image.tiff") print(ka_raster.meta) # 画像の読み込みと強調処理 ka_arr = ka_raster.read() # 5-95% contrast stretch vmin, vmax = np.nanpercentile(ka_arr, (5,95)) # 強調処理した画像の表示 plt.figure(figsize=[10,10]) show(ka_raster, cmap='gray', vmin=vmin, vmax=vmax) plt.show()
出力結果:
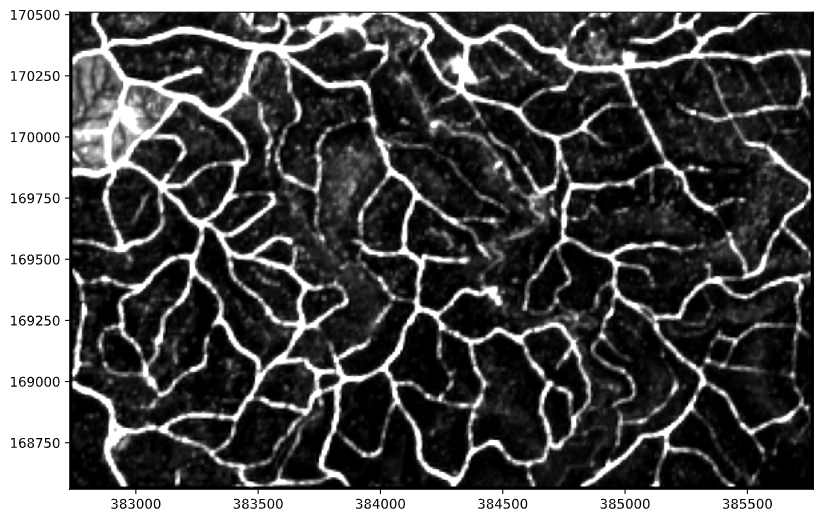
網の目に広がる道路が確認できます。
バンド4とバンド8からNDVIを求める
ではNDVIを求めていきましょう。最初に説明したように、赤色のデータ(バンド4)と近赤外線のデータ(バンド8)から求めます。次のようにすれば、NDVIを求められます。
なお、np.divide(A, B, out=np.zeros_like(A), where=(B!=0)) は、第1引数(A)を第2引数(B)で割る計算を行います。
out=... は計算結果として出力される配列の形式を指定するための引数で、np.zeros_like(A) と書くことで「Aと同じ形をした配列」という指定ができます。また、最後の where=(B!=0) は、ゼロで割り算しないようにするための指定です。Bが0だった場合は、割り算は行わず、0という計算結果が返ります。
# バンド4,8のデータをrasterioで開く b04rst_ca = rio.open('./R10m_ka/T49NCB_20200918T024549_B04_10m.jp2') b08rst_ca = rio.open('./R10m_ka/T49NCB_20200918T024549_B08_10m.jp2') # バンド4,8のデータをndarray(float32)形式にする b04_ca = b04rst_ca.read(1).astype(np.float32) b08_ca = b08rst_ca.read(1).astype(np.float32) # NDVIの算出 # (np.divideを使い、NDVIの算出式の分母が0になる場合は計算結果を0としている) ndvi_ca = np.divide((b08_ca - b04_ca), (b08_ca + b04_ca), out=np.zeros_like(b04_ca), where=((b08_ca + b04_ca)!=0))
このNDVI画像をTIFF形式ファイルとして保存し、切り抜きます。最終的に./ca_image.tiffというファイル名で保存しました。
# kalimantan.tiffのファイル名で保存する with rio.open('./kalimantan.tiff', 'w', driver='GTiff', width=b04rst_ca.width, height=b04rst_ca.height, count=1, # NDVIのみのデータで良いので1とする crs=b04rst_ca.crs, transform=b04rst_ca.transform, dtype='float32' # 8bitの整数への変換はしないので小数値の型を指定する ) as ca_rgb: ca_rgb.write(ndvi_ca, 1) ca_rgb.close() # GeoJSONファイルをGeoPandasで読み込む ca_gpd = gpd.read_file('kalimantan.geojson') # EPGSの仕様に適した形式へGeoJSONデータを変換する ca_gpd_opt = ca_gpd.to_crs({'init': b04rst_ca.crs}) # 切り抜かれたデータを入れる変数(ひとまずNoneで初期化) ca_image = None # 切り抜かれたデータの幅・高さなどの情報を入れる変数(ひとまずNoneで初期化) ca_meta = None # 画像の切り抜き処理 with rio.open('./kalimantan.tiff') as src: # 画像を切り抜いてout_imageに入れる ca_image, ca_transform = rio.mask.mask(src, ca_gpd_opt.geometry, crop=True) # 画像の情報を複製してout_metaに入れる ca_meta = src.meta.copy() # out_metaを切り抜いたあとの画像の情報で更新する ca_meta.update({'driver': 'GTiff', 'height': ca_image.shape[1], 'width': ca_image.shape[2], 'transform': ca_transform, 'dtype': 'float32'}) src.close() # 切り抜いた画像を保存 with rio.open('./ca_image.tiff', 'w', **ca_meta) as dest: dest.write(ca_image) dest.close()
整数化しグレースケール画像として表示する
保存した画像を、植生指標データの0~200の値に変換し、その値をグレースケールの濃度と見なして画像変換して表示すると、次のようになります。
# 切り抜いた画像を読み込む ca_image_nvdi = rio.open('./ca_image.tiff') # -1〜1までのNDVI値を0〜200までの整数値に変換する nvdi_image_data = (((ca_image_nvdi.read(1)) + 1.0) * 100).astype(np.uint8) # グレースケール画像として表示する(明るいところほど植物の植生が良い) plt.imshow(nvdi_image_data, cmap="gray")
出力結果:
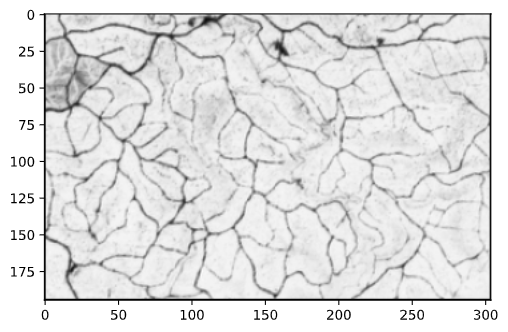
白いところが、植生指標の大きいところ(植物が育成しているところ)、黒いところが小さいところ(植物の少ないところ)です。黒い直線が東西南北に伸びています。これが、農園内に作られた道路です。
画像のノイズ除去
次にフィルタを使って画像のノイズを除去します。フィルターはカリキュラムで紹介したブラーフィルタなどを使っても良いのですが、今回はエッジを残しつつ平滑化を行うバイラテラルフィルタを使用しています。バイラテラルフィルタの使い方は以下のとおりです。
出力画像 = cv2.bilateralFilter(入力画像, ぼかす領域, 色空間の標準偏差, 距離の標準偏差)
「ぼかす領域、色空間の標準偏差、距離の標準偏差」はそれぞれ値が大きいと平滑化しやすくなる反面ぼけやすくなります。画像に応じて適切な値を微調整すると良いでしょう。ここでは、canny法を利用して道路を抽出する際のノイズを除去するために利用しています。
# バイラテラルフィルタの適用 nvdi_image_data2 = cv2.bilateralFilter(nvdi_image_data, 10, 5, 10) # フィルタを適用した画像を表示 plt.imshow(nvdi_image_data2, cmap="gray")
出力結果:
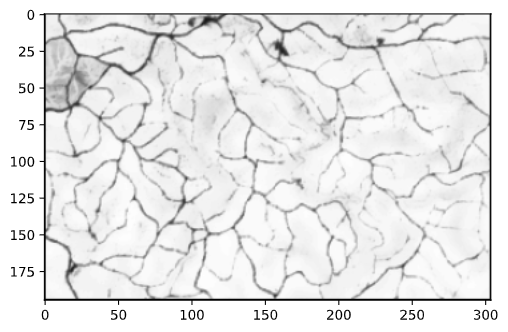
Canny法を使ったエッジ検出
それではここから道路の抽出を試みてみます。はじめはCanny法を使ったエッジの検出です。
# Canny法を使ったエッジを検出 nvdi_edged_canny = cv2.Canny(nvdi_image_data2, 50, 100) # フィルタを適用した結果を表示 plt.imshow(nvdi_edged_canny, cmap="gray")
出力結果:

植生の違いからエッジを検出できました。かなり精度良く道路を抽出することができています。
ラプラシアンフィルタを使ったエッジ抽出
ラプラシアンフィルタとは二次微分を使ったエッジを抽出するフィルタです。線に強く反応するフィルタとして知られています。OpenCVではLaplacian()として実装されています。使い方は以下のとおりです。
出力画像 = cv2.Laplacian(入力画像, 色深度[, オプション])
色深度は画素を表現するビット数を指定します。基本的に入力画像の色深度と同じで良いでしょう。今回はグレースケールを入力画像とするため、色深度は8bit(cv2.CV_8U)を指定しています。また、オプションとして出力を強調するscaleに9を指定しています。値を大きくしすぎると余計な情報を取得し、検出にノイズが生じます。
# ラプラシアンフィルタの適用 nvdi_image_lap = cv2.Laplacian(nvdi_image_data2, cv2.CV_8U, scale=9) # フィルタを適用した結果を表示 plt.imshow(nvdi_image_lap, cmap="gray")
出力結果:
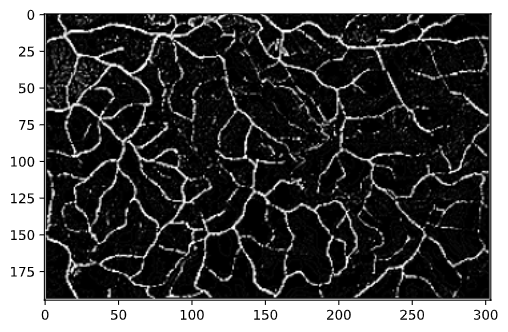
Canny法と比較すると、より繊細にエッジを検出できています。
このままの結果でも道路を検出することができていますが、今回はさらにマスクを適用することで結果がどうなるのかについても考慮して見ます。
マスクの適用
道路は「植生が悪い」部分です。よって植生が悪い部分をマスクとして抽出し、ラプラシアンフィルタで得られた結果と論理積演算することで、よりはっきり道路を抽出できないか、試してみましょう。
まずはマスクを作成します。植生が悪い部分、すなわち値が小さい部分をinRange()関数で取得します。
# 色の強さが180以下の部分をマスクとして取得 nvdi_image_mask = cv2.inRange(nvdi_image_data2, 0, 180) # マスクを表示 plt.imshow(nvdi_image_mask, cmap="gray")
出力結果:

ラプラシアンフィルタの結果と論理積演算を行います。
# ラプラシアンフィルタの結果とマスクの論理積演算 nvdi_image_lap_masked = cv2.bitwise_and(nvdi_image_lap, nvdi_image_mask) # 得られた結果を強調 nvdi_image_lap_masked = cv2.inRange(nvdi_image_lap_masked, 32, 255) # 結果の表示 plt.imshow(nvdi_image_lap_masked, cmap="gray")
出力結果:

さらにエッジを膨張させます。
# エッジを膨張させる kernel = np.ones((2, 2)) / 8.0 nvdi_image_lap_masked2 = cv2.dilate(nvdi_image_lap_masked, kernel) # 膨張させたエッジの画像を表示 plt.imshow(nvdi_image_lap_masked2, cmap="gray")
出力結果:

得られた結果の重ね合わせ
最後にCanny法で得られた結果と重ね合わせて表示してみましょう。
nvdi_image_final = np.zeros((ca_image_nvdi.height, ca_image_nvdi.width, 3), dtype=np.uint8) # Canny法は緑、ラプラシアンフィルタは赤で描画(重なっているところは黄色で表示される) nvdi_image_final[:, :, 1] = nvdi_edged_canny nvdi_image_final[:, :, 2] = nvdi_image_lap_masked2 # 重ね合わせた画像を表示する plt.imshow(cv2.cvtColor(nvdi_image_final, cv2.COLOR_BGR2RGB))
出力結果:

重ね合わせた結果を画像として保存します。
# 重ね合わせた画像を保存する cv2.imwrite('nvdi_image_final.png', nvdi_image_final)
プランテーション農園において縦横無尽に伸びる道路へ色をつけて強調できました。このようにOpenCVの画像処理関数やフィルタを組み合わせることで、画像から多くの情報を得ることができます。
この演習では特定の日時のNVDIを表示しただけですが、たとえば季節変動で植生がどの程度変化するなど、異なる日時の画像で比較すると、植物の生育に影響を与える複数の事象を確認できることでしょう。